


Uma colaboração entre pesquisadores dos Estados Unidos e do Canadá descobriu que modelos de linguagem grandes (LLMs) como o ChatGPT enfrentam dificuldades para reproduzir expressões idiomáticas históricas sem um extenso pré-treinamento – um processo caro e trabalhoso que está além das capacidades da maioria das iniciativas acadêmicas ou de entretenimento, tornando projetos como completar o último romance inacabado de Charles Dickens efetivamente com IA uma proposição improvável.
Os pesquisadores exploraram uma série de métodos para gerar texto que soasse historicamente preciso, começando com uma simples orientação usando prosa do início do século XX e passando para o ajuste fino de um modelo comercial em uma pequena coleção de livros daquele período.
Eles também compararam os resultados com um modelo separado que havia sido treinado inteiramente em livros publicados entre 1880 e 1914.
No primeiro dos testes, instruir o ChatGPT-4o a imitar uma linguagem de fin‑de‑siècle produziu resultados bastante diferentes dos do modelo menor baseado no GPT2 que havia sido ajustado em literatura do período:

Solicitado a completar um texto histórico real (centro superior), mesmo um ChatGPT-4o bem ajustado (inferior esquerda) não consegue evitar voltar ao ‘modo blog’, falhando em representar o idiomatismo solicitado. Em contraste, o modelo GPT2 ajustado (inferior direita) captura bem o estilo da linguagem, mas não é tão preciso de outras maneiras. Fonte: https://arxiv.org/pdf/2505.00030
Embora o ajuste fino traga o output mais próximo do estilo original, leitores humanos ainda conseguiam frequentemente detectar vestígios da linguagem ou ideias modernas, sugerindo que mesmo modelos cuidadosamente ajustados continuam a refletir a influência de seus dados de treinamento contemporâneos.
Os pesquisadores chegaram à frustrante conclusão de que não existem atalhos econômicos para a geração de texto ou diálogo histórico idiomaticamente correto produzido por máquinas. Eles também conjecturam que o desafio em si pode ser mal colocado:
‘[Devemos] também considerar a possibilidade de que o anacronismo pode ser, de certa forma, inevitável. Se representarmos o passado por meio do ajuste de modelos históricos para que eles possam manter conversas, ou ensinando modelos contemporâneos a ventriloquizar uma época mais antiga, pode ser necessário um compromisso entre os objetivos de autenticidade e fluência conversacional.’
‘ Afinal, não existem exemplos “autênticos” de uma conversa entre um questionador do século XXI e um respondente de 1914. Pesquisadores que tentam criar tal conversa precisarão refletir sobre o [premissa] de que a interpretação sempre envolve uma negociação entre o presente e o [passado].’
O novo estudo é intitulado Os Modelos de Linguagem Podem Representar o Passado Sem Anacronismo?, e vem de três pesquisadores da Universidade de Illinois, da Universidade da Colúmbia Britânica e da Universidade Cornell.
Desastre Completo
Inicialmente, em uma abordagem de pesquisa em três partes, os autores testaram se modelos de linguagem modernos poderiam ser induzidos a imitar a linguagem histórica por meio de orientações simples. Usando trechos reais de livros publicados entre 1905 e 1914, pediram ao ChatGPT-4o para continuar essas passagens no mesmo idiomatismo.
O texto original do período era:
‘Neste último caso, economizam-se cerca de cinco ou seis dólares por minuto, pois mais de vinte jardas de filme precisam ser rebobinas para projetar durante um único minuto um objeto de uma pessoa em repouso ou uma paisagem. Assim, obtém-se uma combinação prática de imagens fixas e em movimento, que produz os efeitos artísticos mais notáveis.’
‘Isso também nos permite trabalhar com dois cinematógrafos projetando alternadamente para evitar scintilações, ou projetando simultaneamente imagens vermelhas e verdes e reproduzindo cores naturais, aliviando assim o olho humano, acostumado a receber as cores fundamentais simultaneamente, de toda fadiga fisiológica. Uma palavra agora sobre a aplicação de luz fria à fotografia instantânea.’
Para avaliar se o texto gerado correspondia ao estilo histórico pretendido, e conscientes de que as pessoas não são especialmente habilidosas em adivinhar a data em que um texto foi escrito, os pesquisadores ajustaram um modelo RoBERTa para estimar datas de publicação, usando um subconjunto do Corpus de Inglês Americano Histórico, cobrindo material de 1810 a 2009.
O classificador RoBERTa foi então usado para avaliar continuações produzidas pelo ChatGPT-4o, que havia sido orientado com trechos reais de livros publicados entre 1905 e 1914.
O prompt do sistema (ou seja, instruções contextuais ao ChatGPT sobre como abordar a tarefa) foi:
‘Sua tarefa é completar passagens de livros do início do século XX. Você receberá uma passagem de um livro publicado em 1913. Continue essa passagem no mesmo estilo, por pelo menos 200 palavras. Forneça apenas essa continuação; não faça observações de enquadramento, como ‘aqui está a continuação:’.
Apesar de ambos uma única e 20 vezes de orientação, os outputs do ChatGPT-4o tendiam consistentemente a se inclinar para um registro estilístico do século XXI.
O exemplo fornecido no artigo apresenta uma das tentativas semelhantes a blog do ChatGPT-4o para continuar o texto do período real sobre fotografia:
‘O uso de luz fria na fotografia instantânea revolucionou a abordagem para capturar imagens sob diferentes condições de luz. Tradicionalmente, os fotógrafos lutavam contra as durezas e variabilidades da luz natural ou a natureza intrusiva da fotografia com flash, que poderia perturbar a atmosfera de uma cena ou o comportamento natural dos sujeitos, particularmente na fotografia de vida selvagem e humana espontânea.’
‘A luz fria, com sua natureza mais suave e difusa… permite uma representação mais natural de cores e texturas, que frequentemente se perde sob iluminação artificial dura.’
Como podemos ver facilmente, esse texto genérico e em estilo de wiki não corresponde ao estilo prolixo e elaborado do texto original do período. Além disso, não continua de onde o conteúdo original parou, mas inicia uma divagação abstrata sobre um dos subtemas.
A equipe também testou o GPT‑1914, um modelo menor da classe GPT‑2 treinado desde o início em 26,5 bilhões de tokens de literatura datados entre 1880 e 1914.
Embora seu output fosse menos coerente do que o do ChatGPT-4o, era mais consistente com o estilo da fonte original. O único exemplo fornecido no artigo, novamente como uma continuação do texto do período real sobre fotografia, é:
‘O princípio de sua ação já foi explicado (p. 4). Aqui mencionaremos apenas que pode ser aplicado com vantagem quando desejamos obter fotografias muito rápidas em papel revestido com colódio, assim como aquelas tiradas por meio de placas de gelatina.
‘Nesses casos, a exposição não deve exceder um segundo, pelo menos; mas se a imagem deve ser desenvolvida em menos tempo – digamos meio segundo – então a temperatura não deve cair abaixo de 20° C, caso contrário, a imagem ficará muito escura após o desenvolvimento; além disso, a placa perderia sua sensibilidade nessas condições.
‘Para fins ordinários, no entanto, basta expor a superfície sensível a um nível baixo de calor sem serem necessárias precauções especiais além de manter o’ [sic]
Uma vez que mesmo o material original é arcaico e bastante difícil de seguir, é difícil entender a extensão em que o GPT-1914 captou com precisão o original; mas a saída certamente soa mais autêntica para o período.
No entanto, os autores concluíram a partir deste experimento que a simples orientação não faz muito para superar os preconceitos contemporâneos de um grande modelo pré-treinado como o ChatGPT-4o.
A Trama se Complica
Para medir quão próximos os outputs dos modelos se pareciam com a escrita histórica autêntica, os pesquisadores usaram um classificador estatístico para estimar a data provável de publicação de cada amostra de texto. Eles então visualizaram os resultados usando um gráfico de densidade de kernel, que mostra onde o modelo acha que cada passagem se posiciona em uma linha do tempo histórica.
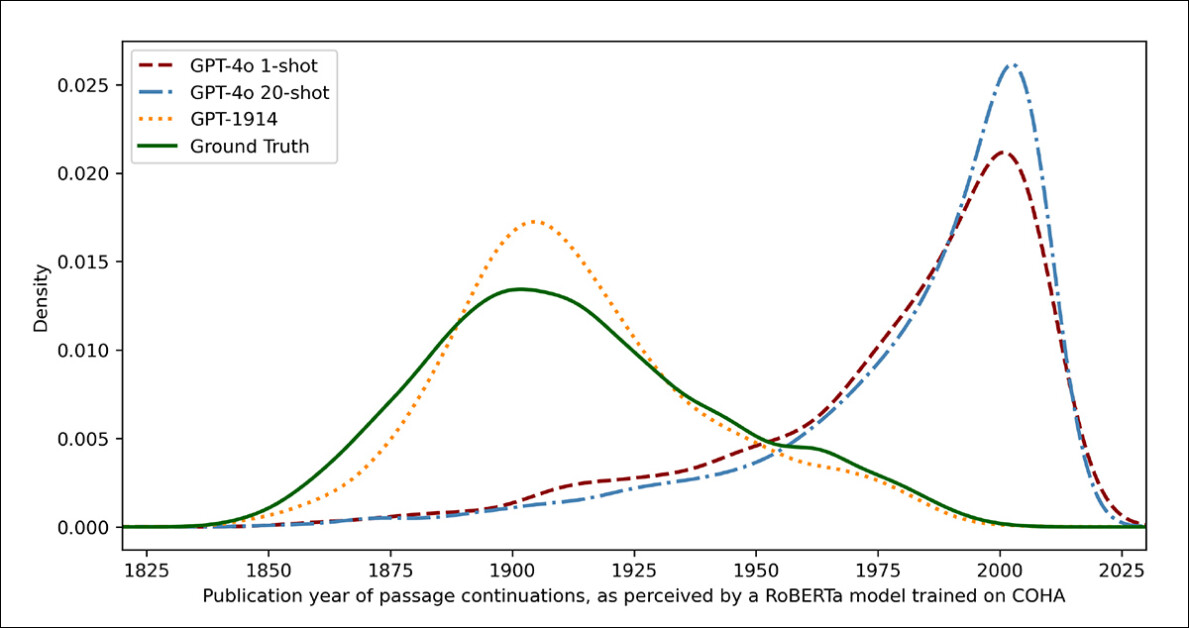
Datas de publicação estimadas para textos reais e gerados, com base em um classificador treinado para reconhecer o estilo histórico (textos de fonte de 1905–1914 comparados com continuações feitas por GPT‑4o usando prompts únicos e de 20 exemplos, e por GPT‑1914 treinado apenas em literatura de 1880–1914).
O modelo RoBERTa ajustado utilizado para essa tarefa, os autores observam, não é infalível, mas foi capaz de destacar tendências estilísticas gerais. Passagens escritas pelo GPT‑1914, o modelo treinado inteiramente em literatura do período, se agruparam em torno do início do século XX – semelhante ao material de origem.
Em contraste, os outputs do ChatGPT-4o, mesmo quando orientados com múltiplos exemplos históricos, tendiam a se assemelhar à escrita do século XXI, refletindo os dados com os quais foi originalmente treinado.
Os pesquisadores quantificaram essa divergência usando divergência Jensen-Shannon, uma medida de quão diferentes duas distribuições de probabilidade são. O GPT-1914 teve uma pontuação próxima de 0,006 em comparação com texto histórico real, enquanto os outputs de uma única orientação e de 20 iterações do ChatGPT-4o mostraram lacunas muito mais amplas, de 0,310 e 0,350, respectivamente.
Os autores argumentam que essas descobertas indicam que apenas a orientação, mesmo com múltiplos exemplos, não é uma maneira confiável de produzir texto que simule convincentemente um estilo histórico.
Completar a Passagem
O artigo então investiga se o ajuste fino poderia produzir um resultado superior, uma vez que esse processo envolve afetar diretamente os pesos utilizáveis de um modelo ao ‘continuar’ seu treinamento com dados especificados pelo usuário – um processo que pode afetar a funcionalidade central original do modelo, mas melhorar significativamente seu desempenho no domínio que está sendo ‘empurrado’ para ele ou enfatizado durante o ajuste fino.
No primeiro experimento de ajuste fino, a equipe treinou o GPT‑4o‑mini em cerca de duas mil pares de passagem-completar extraídos de livros publicados entre 1905 e 1914, com o objetivo de ver se um ajuste fino em menor escala poderia direcionar as saídas do modelo para um estilo mais historicamente preciso.
Usando o mesmo classificador baseado em RoBERTa que uma vez atuou como juiz nos testes anteriores para estimar a ‘data’ estilística de cada output, os pesquisadores descobriram que, no novo experimento, o modelo ajustado produziu textos alinhados com a verdade subjacente.
Sua divergência estilística dos textos originais, medida pela divergência Jensen-Shannon, caiu para 0,002, geralmente alinhada ao GPT‑1914:
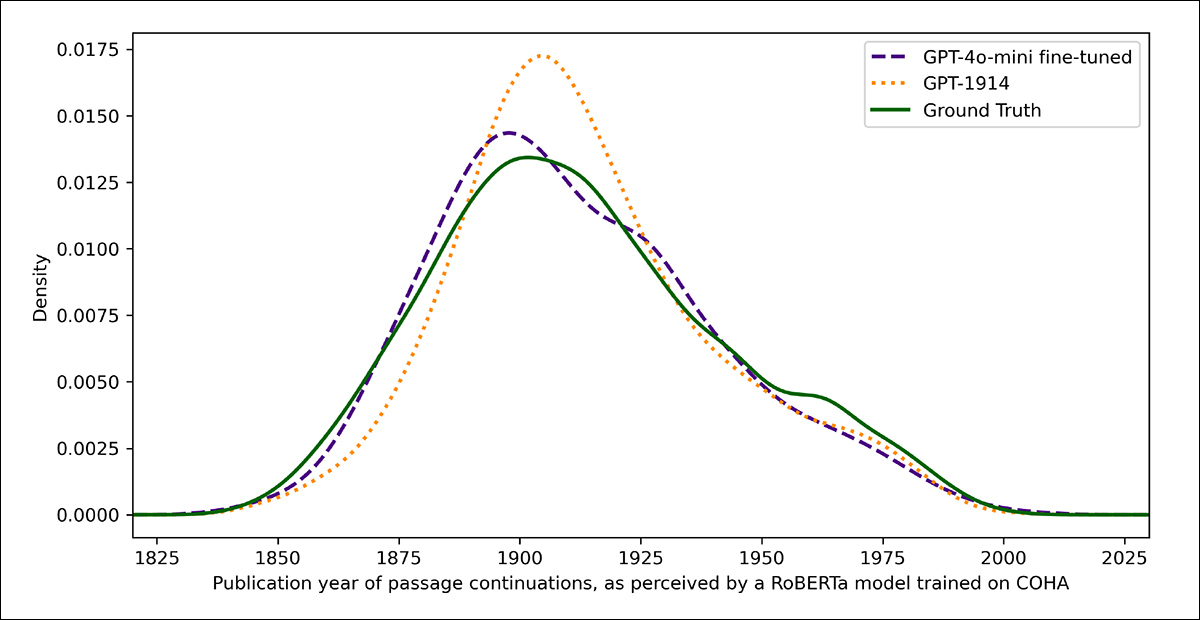
Datas de publicação estimadas para texto real e gerado, mostrando quão de perto o GPT‑1914 e uma versão ajustada do GPT‑4o‑mini coincidem com o estilo da escrita do início do século XX (baseado em livros publicados entre 1905 e 1914).
No entanto, os pesquisadores alertam que essa métrica pode capturar apenas características superficiais do estilo histórico, e não anacronismos conceituais ou factuais mais profundos.
‘[Esse] não é um teste muito sensível. O modelo RoBERTa usado como juiz aqui está apenas treinado para prever uma data, não para discriminar passagens autênticas de anacrônicas. Provavelmente utiliza evidências estilísticas grosseiras para fazer essa previsão. Leitores humanos, ou modelos maiores, ainda podem ser capazes de detectar conteúdo anacrônico em passagens que superficialmente soam “dentro do período”.’
Toque Humano
Finalmente, os pesquisadores conduziram testes de avaliação humana usando 250 passagens selecionadas manualmente de livros publicados entre 1905 e 1914, e observam que muitos desses textos provavelmente seriam interpretados de forma bastante diferente hoje do que na época de sua escrita:
‘Nossa lista incluía, por exemplo, uma entrada de enciclopédia sobre Alsácia (que na época fazia parte da Alemanha) e uma sobre beri-beri (que então muitas vezes era explicada como uma doença fúngica em vez de uma deficiência nutricional). Embora estas sejam diferenças de fato, também selecionamos passagens que exibiriam diferenças mais sutis de atitude, retórica ou imaginação.’
‘Por exemplo, descrições de lugares não europeus no início do século XX tendem a escorregar para generalizações raciais. Uma descrição do nascer do sol na lua escrita em 1913 imagina fenômenos cromáticos ricos, porque ninguém havia visto fotografias de um mundo sem uma [atmosfera].’
Os pesquisadores criaram perguntas curtas que cada passagem histórica poderia plausivelmente responder e então ajustaram o GPT‑4o‑mini em pares de pergunta–resposta. Para fortalecer a avaliação, treinaram cinco versões separadas do modelo, cada vez mantendo uma parte diferente dos dados para teste.
Eles então produziram respostas usando tanto as versões padrão do GPT-4o quanto do GPT-4o‑mini, bem como as variantes ajustadas, cada uma avaliada na parte que não havia visto durante o treinamento.
Perdido no Tempo
Para avaliar quão convincentemente os modelos poderiam imitar a linguagem histórica, os pesquisadores pediram a três anotadores especialistas para revisar 120 completações geradas por IA e julgar se cada uma parecia plausível para um escritor em 1914.
Essa abordagem de avaliação direta provou ser mais desafiadora do que o esperado: embora os anotadores concordassem em suas avaliações quase oitenta por cento do tempo, o desequilíbrio em seus julgamentos (com ‘plausível‘ escolhido o dobro de ‘não plausível‘) significou que seu nível real de concordância foi apenas moderado, conforme medido por um coeficiente kappa de Cohen de 0,554.
Os próprios avaliadores descreveram a tarefa como dificil, muitas vezes exigindo pesquisa adicional para avaliar se uma afirmação estava alinhada com o que era conhecido ou acreditado em 1914.
Algumas passagens levantaram questões difíceis sobre tom e perspectiva – por exemplo, se uma resposta era apropriadamente limitada em sua visão de mundo para refletir o que seria típico em 1914. Esse tipo de julgamento muitas vezes dependia do nível de etnocentrismo (ou seja, a tendência de ver outras culturas através das suposições ou preconceitos da própria).
Nesse contexto, o desafio era decidir se uma passagem expressava apenas preconceito cultural suficiente para parecer historicamente plausível sem soar muito moderna, ou demasiado ofensiva pelos padrões de hoje. Os autores observam que mesmo para acadêmicos familiarizados com o período, foi difícil traçar uma linha nítida entre linguagem que parecia historicamente precisa e linguagem que refletia ideias contemporâneas.
Não obstante, os resultados mostraram uma classificação clara dos modelos, com a versão ajustada do GPT‑4o‑mini considerada a mais plausível em geral:
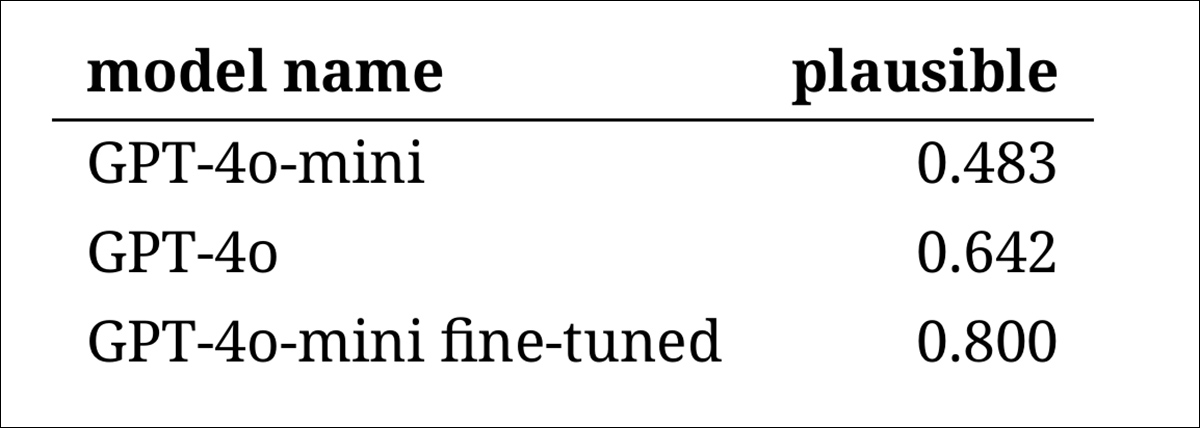
Avaliações dos anotadores sobre a plausibilidade de cada saída do modelo
Se esse nível de desempenho, avaliado como plausível em oitenta por cento dos casos, é confiável o suficiente para pesquisa histórica permanece incerto – particularmente porque o estudo não incluiu uma medida de referência de quão frequentemente textos genuínos do período poderiam ser classificados erroneamente.
Alerta de Intruso
Seguiu-se um ‘teste de intruso’, onde anotadores especialistas foram mostrados quatro passagens anônimas respondendo à mesma questão histórica. Três das respostas vieram de modelos de linguagem, enquanto uma era um trecho real e genuíno de uma fonte do início do século XX.
A tarefa era identificar qual passagem era a original, genuinamente escrita durante o período.
Essa abordagem não pedia aos anotadores para avaliar a plausibilidade diretamente, mas sim mediu com que frequência a passagem real se destacava das respostas geradas pela IA, na prática, testando se os modelos poderiam enganar os leitores fazendo seu output parecer autêntico.
A classificação dos modelos correspondeu aos resultados da tarefa de julgamento anterior: a versão ajustada do GPT‑4o‑mini foi a mais convincente entre os modelos, mas ainda ficou aquém do real.
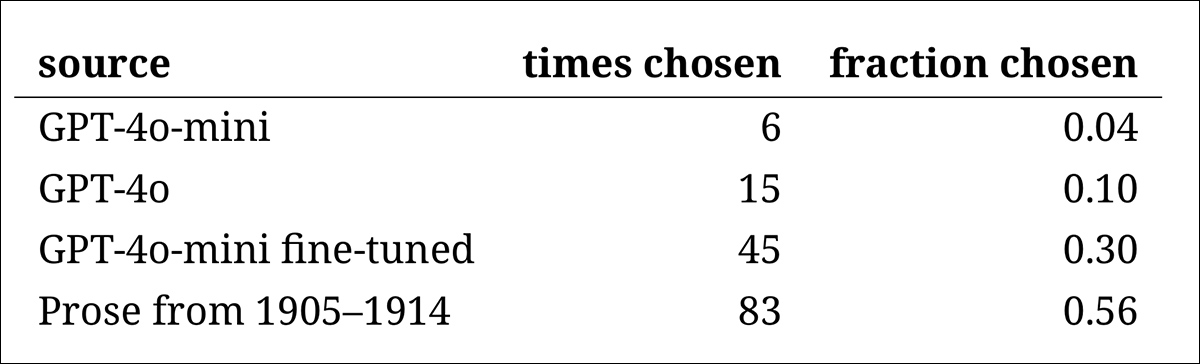
A frequência com que cada fonte foi corretamente identificada como a passagem histórica autêntica.
Esse teste também serviu como um importante referencial, uma vez que, com a passagem genuína identificada mais da metade das vezes, a lacuna entre a prosa autêntica e a sintética ainda se mostrou perceptível para leitores humanos.
Uma análise estatística conhecida como teste de McNemar confirmou que as diferenças entre os modelos eram significativas, exceto no caso das duas versões sem ajuste (GPT‑4o e GPT‑4o‑mini), que tiveram desempenho similar.
O Futuro do Passado
Os autores descobriram que a orientação a modelos de linguagem modernos para adotar uma voz histórica não produziu resultados convincentes de maneira confiável: menos de dois terços das saídas foram julgadas plausíveis por leitores humanos, e mesmo essa cifra provavelmente superestima o desempenho.
Em muitos casos, as respostas incluíam sinais explícitos de que o modelo estava falando de uma perspectiva contemporânea – frases como ‘em 1914, ainda não se sabe que…’ ou ‘até 1914, não estou familiarizado com…’ eram comuns o suficiente para aparecer em até um quinto das completações. Avisos desse tipo deixavam claro que o modelo estava simulando a história de fora, em vez de escrever a partir dela.
Os autores afirmam:
‘O mau desempenho do aprendizado em contexto é infeliz, porque esses métodos são os mais fáceis e baratos para pesquisa histórica baseada em IA. Enfatizamos que não exploramos exaustivamente essas abordagens.
‘Pode ser que o aprendizado em contexto seja adequado – agora ou no futuro – para um subconjunto de áreas de pesquisa. Mas nossas evidências iniciais não são encorajadoras.’
Os autores concluem que, embora o ajuste fino de um modelo comercial em passagens históricas possa produzir uma saída estilisticamente convincente a um custo mínimo, isso não elimina completamente os vestígios de perspectiva moderna. Pré-treinar um modelo inteiramente com material do período evita anacronismos, mas exige recursos muito maiores e resulta em uma saída menos fluente.
Nenhum dos métodos oferece uma solução completa e, por enquanto, qualquer tentativa de simular vozes históricas parece envolver uma troca entre autenticidade e coerência. Os autores concluem que mais pesquisas serão necessárias para esclarecer como navegar essa tensão.
Conclusão
Talvez uma das questões mais interessantes a surgir do novo artigo seja a da autenticidade. Embora não sejam ferramentas perfeitas, funções de perda e métricas como LPIPS e SSIM ofereçam aos pesquisadores de visão computacional pelo menos uma metodologia similar para avaliação em relação à verdade substancial.
Ao gerar novo texto no estilo de uma época passada, em contraste, não há verdade substancial – apenas uma tentativa de habitar uma perspectiva cultural desaparecida. Tentar reconstruir essa mentalidade a partir de vestígios literários é, em si, um ato de quantização, já que tais vestígios são meramente evidências, enquanto a consciência cultural da qual eles emergem permanece além da inferência, e provavelmente além da imaginação.
Em um nível prático também, os fundamentos dos modelos de linguagem modernos, moldados por normas e dados contemporâneos, arriscam reinterpretar ou suprimir ideias que teriam parecido razoáveis ou inócuas para um leitor eduardiano, mas que agora registram como (frequentemente ofensivas) artefatos de preconceito, desigualdade ou injustiça.
Portanto, cabe perguntar se, mesmo que pudéssemos criar tal diálogo, ele poderia não repeli-los.
Publicado pela primeira vez na sexta-feira, 2 de maio de 2025

Conteúdo relacionado

NVIDIA Cosmos: Potencializando a IA Física com Simulações
[the_ad id="145565"] O desenvolvimento de sistemas de IA física, como robôs em fábricas e veículos autônomos nas ruas, depende fortemente de grandes conjuntos de dados de alta…

Apple e Anthropic supostamente se uniram para criar uma plataforma de codificação de IA.
[the_ad id="145565"] A Apple e a Anthropic estão se unindo para criar uma plataforma de software chamada “vibe-coding” que utilizará inteligência artificial generativa para…

Um dos modelos recentes de IA Gemini do Google apresenta pior desempenho em segurança.
[the_ad id="145565"] Um modelo de IA recém-lançado pela Google obteve pontuação pior em certos testes de segurança em comparação ao seu predecessor, de acordo com a avaliação…