


Embora o cinema e a televisão sejam frequentemente vistos como indústrias criativas e abertas, há muito tempo são avessos ao risco. Os altos custos de produção (que podem em breve perder a vantagem compensatória de locais mais baratos no exterior, pelo menos para projetos dos EUA) e um panorama de produção fragmentado tornam difícil para as empresas independentes absorverem uma perda significativa.
Portanto, ao longo da última década, a indústria tem demonstrado um crescente interesse em saber se o aprendizado de máquina pode detectar tendências ou padrões sobre como o público responde a projetos de cinema e televisão propostos.
As principais fontes de dados continuam sendo o sistema Nielsen (que oferece escala, embora suas raízes estejam na TV e na publicidade) e métodos baseados em amostra, como grupos focais, que trocam escala por demografia curada. Esta última categoria também inclui feedback de carteiras de pontuação de pré-estreias gratuitas de filmes — no entanto, nesse ponto, a maior parte do orçamento de uma produção já foi gasta.
A Teoria dos ‘Grandes Sucessos’
Inicialmente, os sistemas de aprendizado de máquina aproveitaram métodos de análise tradicionais, como regressão linear, K-Nearest Neighbors, Stochastic Gradient Descent, Decision Tree e Florestas, e Redes Neurais, geralmente em várias combinações mais próximas do estilo de análise estatística pré-AI, como uma iniciativa de 2019 da Universidade da Flórida Central para prever shows de TV bem-sucedidos com base em combinações de atores e roteiristas (entre outros fatores):
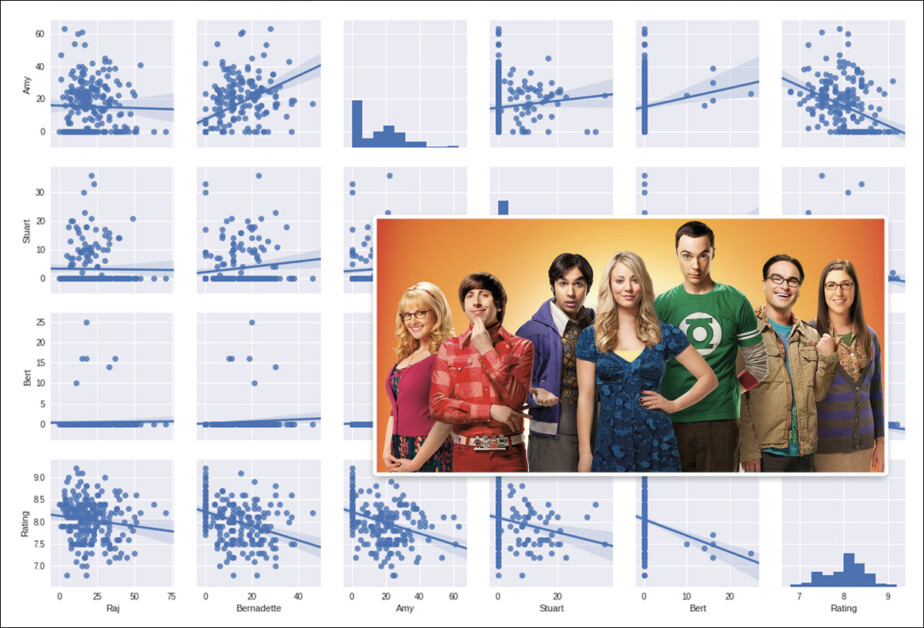
Um estudo de 2018 avaliou o desempenho dos episódios com base em combinações de personagens e/ou roteirista (a maioria dos episódios foi escrita por mais de uma pessoa). Fonte: https://arxiv.org/pdf/1910.12589
O trabalho relacionado mais pertinente, pelo menos aquele que é implementado na prática (embora frequentemente criticado), está no campo dos sistemas de recomendação:
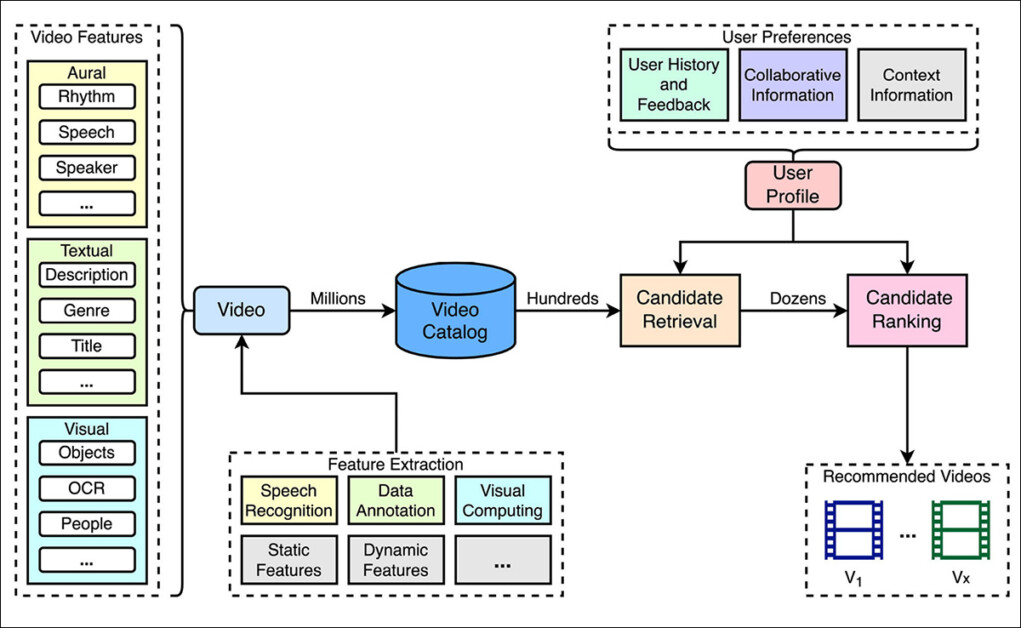
Um pipeline típico de recomendação de vídeo. Os vídeos no catálogo são indexados usando características que podem ser anotadas manualmente ou extraídas automaticamente. As recomendações são geradas em duas etapas, primeiro selecionando vídeos candidatos e depois classificando-os de acordo com um perfil de usuário inferido a partir das preferências de visualização. Fonte: https://www.frontiersin.org/journals/big-data/articles/10.3389/fdata.2023.1281614/full
No entanto, esses tipos de abordagens analisam projetos que já são bem-sucedidos. No caso de novos shows ou filmes prospectivos, não está claro qual tipo de verdade de base seria mais aplicável — não menos porque mudanças no gosto público, combinadas com melhorias e ampliações das fontes de dados, significam que décadas de dados consistentes geralmente não estão disponíveis.
Este é um exemplo do problema de início a frio, onde os sistemas de recomendação devem avaliar candidatos sem nenhum dado de interação anterior. Em tais casos, a filtragem colaborativa tradicional falha, pois depende de padrões de comportamento do usuário (como exibição, avaliação ou compartilhamento) para gerar previsões. O problema é que, no caso da maioria dos novos filmes ou programas, ainda não há feedback suficiente do público para apoiar esses métodos.
A Previsão da Comcast
Um novo artigo da Comcast Technology AI, em associação com a Universidade George Washington, propõe uma solução para esse problema, estimulando um modelo de linguagem com metadados estruturados sobre filmes não lançados.
Os insumos incluem elenco, gênero, sinopse, classificação de conteúdo, humor e prêmios, com o modelo retornando uma lista classificada de hits futuros prováveis.
Os autores usam a saída do modelo como um substituto para o interesse do público quando não há dados de engajamento disponíveis, esperando evitar um viés precoce em relação a títulos que já são bem conhecidos.
O muito curto (três páginas) artigo, intitulado Prevendo Sucessos de Cinema Antes que Aconteçam com LLMs, vem de seis pesquisadores da Comcast Technology AI e um da GWU, e afirma:
Nossos resultados mostram que os LLMs, ao usar metadados de filmes, podem superar significativamente as linhas de base. Essa abordagem pode servir como um sistema assistido para múltiplos casos de uso, permitindo a pontuação automática de grandes volumes de novos conteúdos lançados diariamente e semanalmente.
Ao fornecer insights iniciais antes que as equipes editoriais ou algoritmos tenham acumulado dados de interação suficientes, os LLMs podem agilizar o processo de revisão de conteúdo.
Com melhorias contínuas na eficiência de LLMs e o surgimento de agentes de recomendação, os insights deste trabalho são valiosos e adaptáveis a uma ampla gama de domínios.
Se a abordagem se mostrar robusta, poderá reduzir a dependência da indústria em métricas retrospectivas e títulos amplamente promovidos, introduzindo uma maneira escalável de sinalizar conteúdos promissores antes do lançamento. Assim, em vez de esperar que o comportamento do usuário sinalize a demanda, as equipes editoriais poderiam receber previsões iniciais, baseadas em metadados, do interesse do público, potencialmente redistribuindo a exposição em uma gama mais ampla de novos lançamentos.
Método e Dados
Os autores delineiam um fluxo de trabalho em quatro etapas: a construção de um conjunto de dados dedicado a metadados de filmes não lançados; o estabelecimento de um modelo de linha de base para comparação; a avaliação de LLMs apropriados usando tanto raciocínio em linguagem natural quanto previsão baseada em embedding; e a otimização das saídas através de engenharia de prompt em modo generativo, utilizando os modelos de linguagem Llama 3.1 e 3.3.
Uma vez que, afirmam os autores, nenhum conjunto de dados público oferecia uma forma direta de testar sua hipótese (porque a maioria das coleções existentes é anterior aos LLMs e falta metadados detalhados), eles construíram um conjunto de dados de referência a partir da plataforma de entretenimento da Comcast, que atende dezenas de milhões de usuários através de interfaces diretas e de terceiros.
O conjunto de dados rastreia filmes recém-lançados e se estes se tornaram populares depois, sendo a popularidade definida através de interações dos usuários.
A coleção foca em filmes em vez de séries, e os autores afirmam:
Focamos em filmes porque eles são menos influenciados por conhecimento externo do que séries de TV, melhorando a confiabilidade dos experimentos.
Rótulos foram atribuídos analisando o tempo que levou para um título se tornar popular em diferentes janelas de tempo e tamanhos de lista. O LLM foi estimulado com campos de metadados como gênero, sinopse, classificação, era, elenco, equipe, humor, prêmios, e tipos de personagens.
Para comparação, os autores usaram duas linhas de base: uma ordenação aleatória e um modelo de Embedding Popular (PE) (que abordaremos em breve).
O projeto utilizou grandes modelos de linguagem como o principal método de classificação, gerando listas ordenadas de filmes com pontuações de popularidade previstas e justificativas acompanhantes — e essas saídas foram moldadas por estratégias de engenharia de prompt projetadas para orientar as previsões do modelo com metadados estruturados.
A estratégia de prompt enquadrou o modelo como um “assistente editorial” encarregado de identificar quais filmes futuros eram mais propensos a se tornarem populares, baseando-se exclusivamente em metadados estruturados, e depois encarregado de reordenar uma lista fixa de títulos sem introduzir novos itens, retornando a saída em formato JSON.
Cada resposta consistiu em uma lista classificada, atribuída pontuações de popularidade, justificativas para as classificações e referências a qualquer exemplo anterior que influenciasse o resultado. Esses múltiplos níveis de metadados foram projetados para melhorar a compreensão contextual do modelo e sua capacidade de antecipar tendências futuras do público.
Testes
O experimento seguiu duas etapas principais: inicialmente, os autores testaram várias variantes do modelo para estabelecer uma linha de base, envolvendo a identificação da versão que apresentou desempenho melhor do que uma abordagem de ordenação aleatória.
Em segundo lugar, eles testaram grandes modelos de linguagem em modo generativo, comparando sua saída a uma linha de base mais forte, em vez de um ranking aleatório, aumentando a dificuldade da tarefa.
Isso significou que os modelos precisavam ter um desempenho melhor do que um sistema que já mostrava alguma capacidade de prever quais filmes se tornariam populares. Como resultado, os autores afirmam que a avaliação refletiu melhor as condições do mundo real, onde equipes editoriais e sistemas de recomendação raramente escolhem entre um modelo e a sorte, mas entre sistemas concorrentes com níveis variados de capacidade preditiva.
A Vantagem da Ignorância
Uma limitação chave nesse arranjo foi o intervalo de tempo entre o prazo de conhecimento dos modelos e as datas de lançamento reais dos filmes. Como os modelos de linguagem foram treinados com dados que terminaram seis a doze meses antes de os filmes se tornarem disponíveis, eles não tinham acesso a informações pós-lançamento, garantindo que as previsões fossem baseadas exclusivamente em metadados e não em qualquer resposta do público aprendida.
Avaliação de Linha de Base
Para construir uma linha de base, os autores geraram representações semânticas de metadados de filmes usando três modelos de embedding: BERT V4; Linq-Embed-Mistral 7B; e Llama 3.3 70B, quantizado para 8 bits de precisão para atender às restrições do ambiente experimental.
O Linq-Embed-Mistral foi selecionado para inclusão devido à sua posição de destaque na tabela de classificação do MTEB (Massive Text Embedding Benchmark) liderança.
Cada modelo produziu embeddings vetoriais de filmes candidatos, que foram então comparados à média de embedding dos cem títulos mais populares das semanas anteriores ao lançamento de cada filme.
A popularidade foi inferida usando similaridade do cosseno entre esses embeddings, com escores de similaridade mais altos indicando maior apelo previsto. A precisão do ranking de cada modelo foi avaliada medindo o desempenho em comparação com uma linha de base de ordenação aleatória.
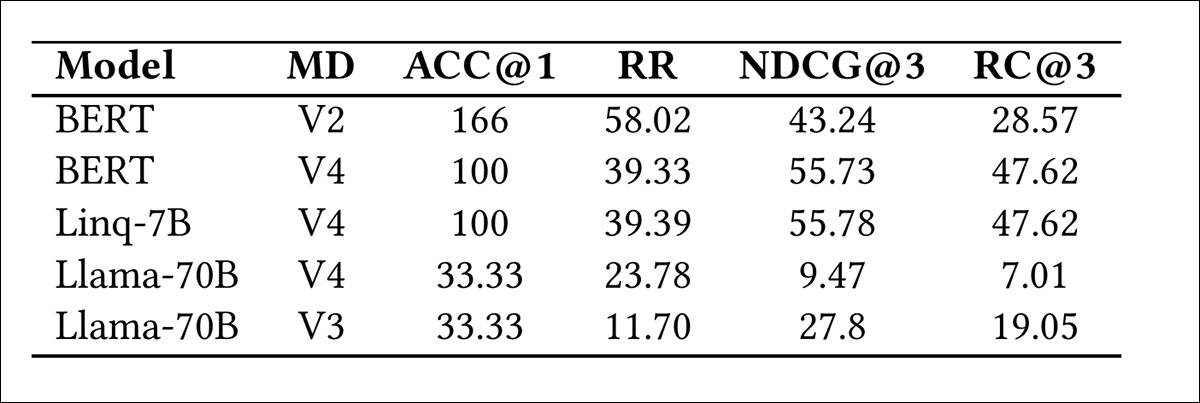
Melhora de desempenho dos modelos de Embedding Popular em comparação a uma linha de base aleatória. Cada modelo foi testado usando quatro configurações de metadados: V1 inclui apenas gênero; V2 inclui apenas sinopse; V3 combina gênero, sinopse, classificação de conteúdo, tipos de personagem, humor e era de lançamento; V4 adiciona elenco, equipe e prêmios à configuração V3. Os resultados mostram como entradas de metadados mais ricas afetam a precisão do ranking. Fonte: https://arxiv.org/pdf/2505.02693
Os resultados (mostrados acima) demonstram que o BERT V4 e o Linq-Embed-Mistral 7B entregaram as melhores melhorias na identificação dos três títulos mais populares, embora ambos tenham ficado um pouco aquém na previsão do item mais popular.
O BERT foi selecionado como o modelo de linha de base para comparação com os LLMs, pois sua eficiência e ganhos gerais superaram suas limitações.
Avaliação de LLM
Os pesquisadores avaliaram o desempenho usando duas abordagens de classificação: pairwise e listwise. A classificação em pares avalia se o modelo ordena corretamente um item em relação ao outro; e a classificação listwise considera a precisão de toda a lista ordenada de candidatos.
Essa combinação possibilitou avaliar não apenas se pares de filmes individuais foram classificados corretamente (precisão local), mas também quão bem a lista completa de candidatos refletiu a verdadeira ordem de popularidade (precisão global).
Modelos completos, não quantizados, foram empregados para evitar perda de desempenho, garantindo uma comparação consistente e reprodutível entre previsões baseadas em LLM e linhas de base baseadas em embedding.
Métricas
Para avaliar quão efetivamente os modelos de linguagem previram a popularidade de filmes, foram usadas métricas baseadas em classificação e ranking, com atenção especial à identificação dos três títulos mais populares.
Quatro métricas foram aplicadas: Accuracy@1 mediu com que frequência o item mais popular apareceu na primeira posição; o Rank Recíproco capturou quão alto o item real mais popular foi classificado na lista prevista, levando em conta o inverso de sua posição; Normalized Discounted Cumulative Gain (NDCG@k) avaliou o quão bem toda a classificação coincidiu com a popularidade real, com scores mais altos indicando melhor alinhamento; e Recall@3 mediu a proporção de títulos realmente populares que apareceram nas três principais previsões do modelo.
Uma vez que a maior parte do engajamento do usuário ocorre perto do topo dos menus classificados, a avaliação focou em valores menores de k, para refletir casos de uso práticos.
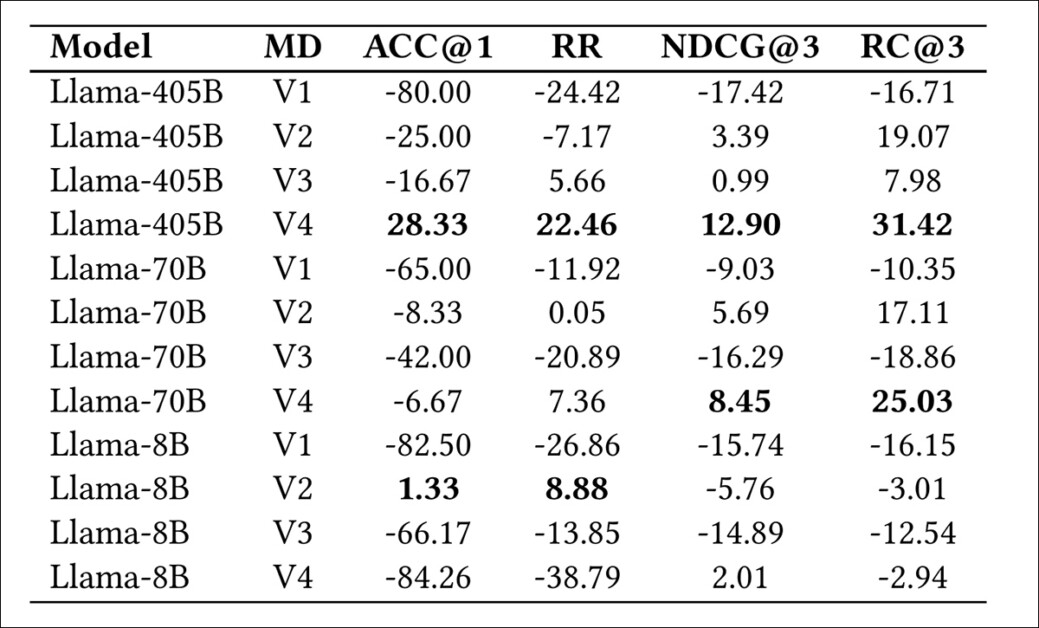
Melhora de desempenho dos modelos de linguagem grande sobre BERT V4, medida como ganhos percentuais em métricas de ranking. Os resultados foram averageados em dez execuções por combinação de modelo-prompt, com os dois valores principais destacados. Os números relatados refletem a média percentual de melhoria em todas as métricas.
O desempenho dos modelos Llama 3.1 (8B), 3.1 (405B) e 3.3 (70B) foi avaliado medindo melhorias nas métricas relativas à linha de base BERT V4 estabelecida anteriormente. Cada modelo foi testado usando uma série de prompts, variando de mínimos a ricos em informações, para examinar o efeito do detalhe da entrada na qualidade da previsão.
Os autores afirmam:
A melhor performance é alcançada ao usar Llama 3.1 (405B) com o prompt mais informativo, seguido pelo Llama 3.3 (70B). Com base na tendência observada, ao usar um prompt complexo e longo (MD V4), um modelo de linguagem mais complexo geralmente leva a uma performance melhor nas várias métricas. No entanto, ele é sensível ao tipo de informação adicionada.
A performance melhorou quando prêmios do elenco foram incluídos como parte do prompt — neste caso, o número de grandes prêmios recebidos pelos cinco atores mais bem classificados de cada filme. Esses metadados mais ricos eram parte da configuração de prompt mais detalhada, superando uma versão mais simples que excluía o reconhecimento do elenco. O benefício foi mais evidente nos modelos maiores, Llama 3.1 (405B) e 3.3 (70B), ambos mostraram maior precisão preditiva ao receber este sinal adicional de prestígio e familiaridade do público.
Por outro lado, o menor modelo, Llama 3.1 (8B), mostrou melhor desempenho à medida que os prompts se tornavam ligeiramente mais detalhados, progredindo de gênero para sinopse, mas caiu quando mais campos foram adicionados, sugerindo que o modelo não tinha a capacidade de integrar prompts complexos efetivamente, levando a uma generalização mais fraca.
Quando os prompts foram restritos apenas ao gênero, todos os modelos tiveram desempenho inferior em comparação com a linha de base, demonstrando que metadados limitados eram insuficientes para sustentar previsões significativas.
Conclusão
Os LLMs se tornaram o símbolo do AI generativa, o que pode explicar por que estão sendo utilizados em áreas onde outros métodos poderiam ser mais adequados. Mesmo assim, ainda há muito que não sabemos sobre o que eles podem fazer em diferentes indústrias, então faz sentido tentar.
Neste caso específico, assim como nos mercados de ações e na previsão do tempo, há apenas uma extensão limitada à qual dados históricos podem servir como base para previsões futuras. No caso de filmes e programas de TV, o próprio método de entrega agora é um alvo em movimento, em contraste com o período de 1978 a 2011, quando cabo, satélite e mídia portátil (VHS, DVD, etc.) representavam uma série de interrupções históricas transitórias ou em evolução.
Além disso, nenhum método de previsão pode contabilizar a extensão em que o sucesso ou fracasso de outras produções pode influenciar a viabilidade de uma propriedade proposta — e isso é frequentemente o caso na indústria do cinema e da TV, que adora seguir uma tendência.
Não obstante, quando utilizados de forma ponderada, os LLMs podem ajudar a fortalecer os sistemas de recomendação durante a fase de início a frio, oferecendo suporte útil a uma gama de métodos preditivos.
Publicado pela primeira vez na terça-feira, 6 de maio de 2025

Conteúdo relacionado

Hugging Face lança uma ferramenta de IA agente semelhante ao Operator de forma gratuita.
[the_ad id="145565"] Uma equipe da Hugging Face lançou um agente de IA “que usa computador” disponível gratuitamente e hospedado na nuvem. Mas esteja avisado: é bastante lento…

Ōura adiciona recursos de rastreamento de refeições e glicose com inteligência artificial em parceria com a Stelo da Dexcom.
[the_ad id="145565"] Ōura, fabricante de um anel inteligente para monitoramento de saúde, anunciou que utilizará IA para rastrear e analisar duas novas funcionalidades de saúde…

A startup Korl lança ferramenta multimodal e multiagente para comunicação personalizada entre sistemas distintos.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdos exclusivos sobre cobertura de IA de ponta. Saiba mais…