


Participe de nossos boletins diários e semanais para obter as últimas atualizações e conteúdo exclusivo sobre coberturas de IA de ponta. Saiba mais
Pesquisadores da Mem0 apresentaram duas novas arquiteturas de memória projetadas para permitir que Modelos de Linguagem de Grande Escala (LLMs) mantenham conversas coerentes e consistentes ao longo do tempo.
Suas arquiteturas, chamadas Mem0 e Mem0g, extraem, consolidam e recuperam dinamicamente informações-chave das conversas. Elas são projetadas para proporcionar aos agentes de IA uma memória mais humana, especialmente em tarefas que exigem lembranças de longas interações.
Esse desenvolvimento é particularmente significativo para empresas que buscam implementar agentes de IA mais confiáveis para aplicações que abrangem fluxos de dados muito longos.
A importância da memória em agentes de IA
Os LLMs demonstraram habilidades incríveis em gerar texto semelhante ao humano. No entanto, suas janelas de contexto fixas impõem uma limitação fundamental à sua capacidade de manter a coerência em diálogos longos ou em múltiplas sessões.
Mesmo que janelas de contexto cheguem a milhões de tokens, isso não é uma solução completa por duas razões, afirmam os pesquisadores por trás da Mem0.
- À medida que relacionamentos humanos-IA significativos se desenvolvem ao longo de semanas ou meses, o histórico da conversa inevitavelmente crescerá além dos limites de contexto mais generosos.
- Conversas do mundo real raramente se restringem a um único tópico. Um LLM que depende apenas de uma janela de contexto massiva teria que filtrar montanhas de dados irrelevantes para cada resposta.
Além disso, simplesmente alimentar um LLM com um contexto mais longo não garante que ele irá recuperar ou usar efetivamente informações passadas. Os mecanismos de atenção que os LLMs usam para pesar a importância de diferentes partes da entrada podem se degradar ao longo de tokens distantes, o que significa que informações enterradas em uma longa conversa podem ser negligenciadas.
“Em muitos sistemas de IA em produção, abordagens tradicionais de memória rapidamente atingem seus limites,” disse Taranjeet Singh, CEO da Mem0 e coautor do artigo, ao VentureBeat.
Por exemplo, bots de atendimento ao cliente podem esquecer pedidos de reembolso anteriores e exigem que você reintroduza os detalhes do pedido sempre que retornar. Assistentes de planejamento podem lembrar seu itinerário de viagem, mas rapidamente perdem de vista seu assento ou preferências alimentares na próxima sessão. Assistentes de saúde podem falhar em recordar alergias previamente relatadas ou condições crônicas e fornecer orientações inseguras.
“Essas falhas decorrem de contextos rígidos com janelas fixas ou métodos de recuperação simplistas que ou reprocessam todo o histórico (aumentando a latência e o custo) ou negligenciam fatos importantes enterrados em longas transcrições,” disse Singh.
Em seu artigo, os pesquisadores argumentam que uma memória de IA robusta deve “armazenar seletivamente informações importantes, consolidar conceitos relacionados e recuperar detalhes relevantes quando necessário—refletindo processos cognitivos humanos.”
Mem0
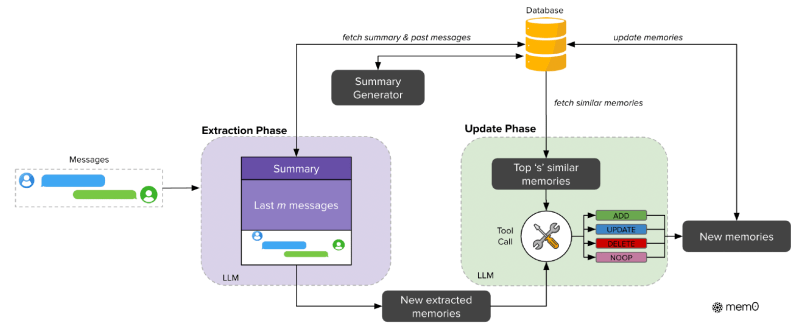
A Mem0 é projetada para capturar, organizar e recuperar dinamicamente informações relevantes de conversas em andamento. Sua arquitetura em pipeline consiste em duas fases principais: extração e atualização.
A fase de extração começa quando um novo par de mensagens é processado (normalmente uma mensagem do usuário e a resposta do assistente de IA). O sistema adiciona contexto de duas fontes de informação: uma sequência de mensagens recentes e um resumo de toda a conversa até o momento. A Mem0 utiliza um módulo de geração de resumo assíncrono que periodicamente atualiza o resumo da conversa em segundo plano.
Com esse contexto, o sistema então extrai um conjunto de memórias importantes especificamente da nova troca de mensagens.
A fase de atualização então avalia esses “fatos candidatos” recém-extraídos em comparação com as memórias existentes. A Mem0 aproveita as próprias capacidades de raciocínio do LLM para determinar se deve adicionar o novo fato caso não existam memórias semanticamente semelhantes; atualizar uma memória existente se o novo fato fornecer informações complementares; excluir uma memória se o novo fato a contradizer; ou não fazer nada se o fato já estiver bem representado ou for irrelevante.
“Ao espelhar a recuperação seletiva humana, a Mem0 transforma os agentes de IA de respondentes esquecidos em parceiros confiáveis capazes de manter a coerência ao longo de dias, semanas ou até meses,” disse Singh.
Mem0g
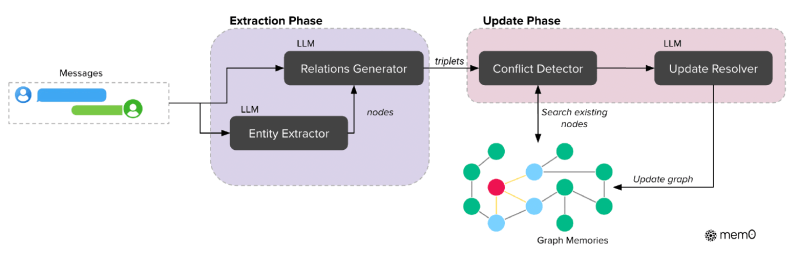
Baseando-se na fundação da Mem0, os pesquisadores desenvolveram o Mem0g (Mem0-grafo), que aprimora a arquitetura base com representações de memória baseadas em grafos. Isso permite um modelamento mais sofisticado de relacionamentos complexos entre diferentes pedaços de informações conversacionais. Em uma memória baseada em grafos, entidades (como pessoas, locais ou conceitos) são representadas como nós, e os relacionamentos entre elas (como “mora em” ou “prefere”) são representados como arestas.
Como o artigo explica: “Ao modelar explicitamente tanto entidades quanto seus relacionamentos, a Mem0g suporta raciocínios mais avançados entre fatos interconectados, especialmente para consultas que requerem navegação por caminhos relacionais complexos através de múltiplas memórias.” Por exemplo, entender o histórico de viagens e preferências de um usuário pode envolver vincular múltiplas entidades (cidades, datas, atividades) por meio de várias relações.
A Mem0g usa um pipeline de duas etapas para transformar texto de conversa não estruturado em representações gráficas.
- Primeiro, um módulo extrator de entidades identifica elementos-chave de informação (pessoas, locais, objetos, eventos, etc.) e seus tipos.
- Em seguida, um componente gerador de relacionamentos deriva conexões significativas entre essas entidades para criar tríades de relacionamento que formam as arestas do grafo de memória.
A Mem0g inclui um mecanismo de detecção de conflitos para identificar e resolver conflitos entre novas informações e relacionamentos existentes no grafo.
Resultados impressionantes em desempenho e eficiência
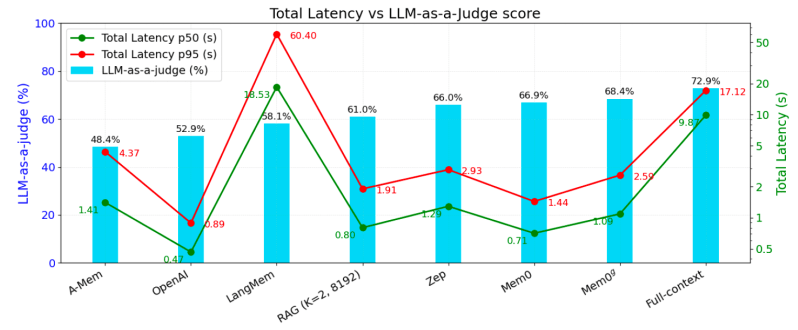
Os pesquisadores realizaram avaliações abrangentes no benchmark LOCOMO, um conjunto de dados projetado para testar a memória conversacional de longo prazo. Além de métricas de precisão, utilizaram uma abordagem “LLM-como-Julgador” para métricas de desempenho, onde um LLM separado avalia a qualidade da resposta do modelo principal. Eles também rastrearam o consumo de tokens e a latência de resposta para avaliar as implicações práticas das técnicas.
A Mem0 e a Mem0g foram comparadas com seis categorias de baseline, incluindo sistemas de memória aumentada estabelecidos, várias configurações de Geração Aumentada por Recuperação (RAG), uma abordagem de contexto completo (alimentando a conversa inteira para o LLM), uma solução de memória de código aberto, um sistema proprietário (recurso de memória do ChatGPT da OpenAI) e uma plataforma de gerenciamento de memória dedicada.
Os resultados mostram que tanto a Mem0 quanto a Mem0g superam ou igualam consistentemente os sistemas de memória existentes em vários tipos de perguntas (de um único passo, múltiplos passos, temporais e de domínio aberto), enquanto reduzem significativamente a latência e os custos computacionais. Por exemplo, a Mem0 alcança uma latência 91% menor e economiza mais de 90% nos custos de tokens em comparação com a abordagem de contexto completo, mantendo uma qualidade de resposta competitiva. A Mem0g também demonstra um desempenho forte, especialmente em tarefas que exigem raciocínio temporal.
“Esses avanços sublinham a vantagem de capturar apenas os fatos mais salientes na memória, em vez de recuperar grandes blocos de texto original,” escrevem os pesquisadores. “Ao converter o histórico da conversa em representações estruturadas e concisas, a Mem0 e Mem0g mitigam o ruído e ressaltam indícios mais precisos para o LLM, levando a melhores respostas avaliadas por um LLM externo.”
Como escolher entre Mem0 e Mem0g
“Escolher entre o motor Mem0 básico e sua versão aprimorada com gráfico, Mem0g, acaba por depender da natureza do raciocínio que sua aplicação necessita e dos trade-offs que você está disposto a fazer entre velocidade, simplicidade e poder inferencial,” disse Singh.
A Mem0 é mais adequada para recordação de fatos simples, como lembrar o nome de um usuário, o idioma preferido ou uma decisão pontual. Seus “fatos de memória” em linguagem natural são armazenados como trechos de texto concisos, e as pesquisas são concluídas em menos de 150ms.
“Esse design de baixa latência e baixo custo torna a Mem0 ideal para chatbots em tempo real, assistentes pessoais e qualquer cenário onde cada milissegundo e token contam,” afirmou Singh.
Em contraste, quando seu caso de uso exige raciocínio relacional ou temporal, como responder “Quem aprovou esse orçamento, e quando?”, encadear um itinerário de viagem em múltiplas etapas ou rastrear o plano de tratamento em evolução de um paciente, a camada de grafo de conhecimento da Mem0g é a melhor opção.
“Embora consultas em grafo introduzam um modesto custo de latência em comparação com a Mem0 simples, o retorno é um poderoso motor relacional que pode lidar com estados em evolução e fluxos de trabalho multiagente,” disse Singh.
Para aplicações empresariais, Mem0 e Mem0g podem fornecer agentes de IA conversacional mais confiáveis e eficientes que conversam fluentemente e lembram, aprendem e constroem sobre interações passadas.
“Essa transição de pipelines efêmeros, que se atualizam a cada consulta, para um modelo de memória em evolução e viva é crítica para copilotos empresariais, colegas de IA e agentes digitais autônomos—onde coerência, confiança e personalização não são recursos opcionais, mas a própria base de sua proposta de valor,” disse Singh.


Conteúdo relacionado

DeepSeek-Prover-V2: Unindo a Lógica Informal e Formal no Raciocínio Matemático
[the_ad id="145565"] Enquanto o DeepSeek-R1 avançou significativamente nas capacidades da IA em raciocínio informal, o raciocínio matemático formal continua a ser uma tarefa…

CoreWeave supostamente busca levantar $1,5 bilhão em dívida após desilusão com o IPO.
[the_ad id="145565"] A operadora de data center CoreWeave está supostamente buscando um acordo de dívida de US$ 1,5 bilhão após um IPO decepcionante. De acordo com o Financial…

Meta está acelerando o pipeline de ‘Mad Men para Math Men’
[the_ad id="145565"] Sure! Here’s the rewritten content with HTML tags in Portuguese: <meta name="description" content="A Meta está acelerando o processo de transformação de…