


Assine nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA de ponta. Saiba mais
Duas abordagens populares para adaptar grandes modelos de linguagem (LLMs) para tarefas específicas são o fine-tuning e o aprendizado em contexto (ICL). Em um estudo recente, pesquisadores da Google DeepMind e da Universidade de Stanford exploraram as capacidades de generalização desses dois métodos. Eles descobriram que o ICL apresenta maior capacidade de generalização (embora venha com um custo computacional mais alto durante a inferência). Eles também propuseram uma abordagem inovadora para obter o melhor dos dois mundos.
As descobertas podem ajudar os desenvolvedores a tomarem decisões cruciais ao construir aplicações de LLM para seus dados empresariais personalizados.
Teste de como os modelos de linguagem aprendem novas habilidades
O fine-tuning envolve pegar um LLM pré-treinado e treiná-lo ainda mais em um conjunto de dados menor e especializado. Isso ajusta os parâmetros internos do modelo para ensinar novas informações ou habilidades. O aprendizado em contexto (ICL), por outro lado, não altera os parâmetros subjacentes do modelo. Em vez disso, orienta o LLM fornecendo exemplos da tarefa desejada diretamente dentro do prompt de entrada. O modelo, então, utiliza esses exemplos para entender como lidar com uma nova consulta semelhante.
Os pesquisadores se propuseram a comparar rigorosamente como os modelos generalizam novas tarefas usando esses dois métodos. Eles construíram “conjuntos de dados sintéticos controlados de conhecimento factual” com estruturas complexas e autossustentáveis, como árvores genealógicas imaginárias ou hierarquias de conceitos fictícios.
Para garantir que estavam testando a capacidade do modelo de aprender novas informações, substituiram todos os substantivos, adjetivos e verbos por termos sem sentido, evitando qualquer sobreposição com os dados que os LLMs poderiam ter encontrado durante o pré-treinamento.
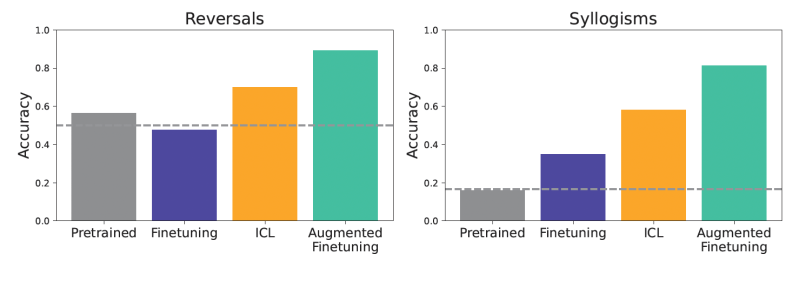
Os modelos foram testados em vários desafios de generalização. Por exemplo, um teste envolveu reversões simples. Se um modelo foi treinado para entender que “femp é mais perigoso que glon,” poderia inferir corretamente que “glon é menos perigoso que femp”? Outro teste focou em silogismos simples, uma forma de dedução lógica. Se informado que “Todos os glon são yomp” e “Todos os troff são glon,” o modelo poderia deduzir que “Todos os troff são yomp”? Eles também utilizaram um “benchmark de estrutura semântica” mais complexo com uma hierarquia mais rica desses fatos inventados para testar uma compreensão mais sutil.
“Nossos resultados se concentraram principalmente em configurações sobre como os modelos generalizam deduções e reversões do fine-tuning em novas estruturas de conhecimento, com claras implicações para situações em que o fine-tuning é usado para adaptar um modelo a informações específicas e proprietárias de uma empresa,” disse Andrew Lampinen, Cientista de Pesquisa da Google DeepMind e autor principal do artigo, ao VentureBeat.
Para avaliar o desempenho, os pesquisadores realizaram o fine-tuning do Gemini 1.5 Flash nesses conjuntos de dados. Para o ICL, alimentaram todo o conjunto de dados de treinamento (ou grandes subconjuntos) como contexto para um modelo ajustado por instruções antes de apresentar as perguntas de teste.
Os resultados mostraram consistentemente que, em configurações de dados correspondentes, o ICL levou a uma melhor generalização do que o fine-tuning padrão. Os modelos que usaram ICL foram geralmente melhores em tarefas como reverter relacionamentos ou fazer deduções lógicas a partir do contexto fornecido. Modelos pré-treinados, sem fine-tuning ou ICL, apresentaram desempenho insatisfatório, indicando a novidade dos dados de teste.
“Um dos principais trade-offs a considerar é que, enquanto o ICL não requer fine-tuning (o que economiza custos de treinamento), é geralmente mais dispendioso computacionalmente a cada uso, já que precisa fornecer contexto adicional ao modelo,” disse Lampinen. “Por outro lado, o ICL tende a generalizar melhor para os conjuntos de dados e modelos que avaliamos.”
Uma abordagem híbrida: Aumentando o fine-tuning
Com base na observação de que o ICL se destaca na generalização flexível, os pesquisadores propuseram um novo método para aprimorar o fine-tuning: adicionar inferências em contexto aos dados de fine-tuning. A ideia central é utilizar as próprias capacidades de ICL do LLM para gerar exemplos mais diversos e ricos em inferências, e então adicionar esses exemplos augmentados ao conjunto de dados usado para o fine-tuning.
Exploraram duas principais estratégias de aumento de dados:
- Uma estratégia local: Esta abordagem foca em informações individuais. O LLM é solicitado a reformular frases únicas dos dados de treinamento ou fazer inferências diretas a partir delas, como gerar reversões.
- Uma estratégia global: O LLM recebe todo o conjunto de dados de treinamento como contexto e, em seguida, é solicitado a gerar inferências vinculando um documento ou fato específico ao resto das informações fornecidas, levando a uma sequência de raciocínio mais longa de inferências relevantes.
Quando os modelos foram ajustados em conjuntos de dados aumentados, os ganhos foram significativos. Esse fine-tuning aumentado melhorou consideravelmente a generalização, superando não apenas o fine-tuning padrão, mas também o ICL simples.
“Por exemplo, se um dos documentos da empresa diz ‘XYZ é uma ferramenta interna para análise de dados’, nossos resultados sugerem que ICL e fine-tuning aumentado serão mais eficazes ao permitir que o modelo responda a perguntas relacionadas como ‘Quais ferramentas internas para análise de dados existem?’” disse Lampinen.
Essa abordagem oferece um caminho convincente para as empresas. Ao investir na criação desses conjuntos de dados aumentados por ICL, os desenvolvedores podem construir modelos finamente ajustados que exibem capacidades de generalização mais fortes.
Isso pode levar a aplicações de LLM mais robustas e confiáveis que se saem melhor em entradas reais e diversas, sem incorrer nos custos contínuos de inferência associados a grandes prompts em contexto.
“O fine-tuning aumentado tornará o processo de fine-tuning do modelo geralmente mais caro, porque requer uma etapa adicional de ICL para aumentar os dados, seguida do fine-tuning,” disse Lampinen. “Se esse custo adicional é justificado pela melhor generalização dependerá do caso de uso específico. No entanto, é computacionalmente mais barato do que aplicar ICL toda vez que o modelo é usado, quando amortizado por muitos usos do modelo.”
Embora Lampinen tenha observado que mais pesquisas são necessárias para ver como os componentes que estudaram interagem em diferentes configurações, ele acrescentou que suas descobertas indicam que os desenvolvedores podem querer considerar explorar o fine-tuning aumentado em casos onde veem desempenho inadequado apenas com fine-tuning.
“No fim, esperamos que este trabalho contribua para a ciência de entender o aprendizado e a generalização em modelos fundamentais, e as práticas de adaptá-los a tarefas específicas,” disse Lampinen.


Conteúdo relacionado

Microsoft Build 2025: O que esperar, desde atualizações do Azure até melhorias no Copilot
[the_ad id="145565"] A Microsoft realizará sua conferência anual Build para desenvolvedores na próxima semana, de 19 a 22 de maio. O evento certamente incluirá anúncios sobre…

Aarki lança Encore como plataforma de crescimento móvel com foco em privacidade
[the_ad id="145565"] Aarki lançou o Encore, uma plataforma de machine learning de próxima geração desenvolvida para oferecer crescimento de funil completo para os profissionais…

De silício à sentiência: O legado que guia a próxima fronteira da IA e a migração cognitiva humana.
[the_ad id="145565"] Assine nossas newsletters diárias e semanais para obter as últimas atualizações e conteúdos exclusivos sobre a cobertura de IA líder do setor. Saiba mais……