


Um novo artigo de pesquisadores da China e da Espanha revela que até mesmo modelos avançados de IA multimodal, como o GPT-4.1, têm dificuldades em dizer as horas a partir de imagens de relógios analógicos. Pequenas mudanças visuais nos relógios podem causar grandes erros de interpretação, e o ajuste fino ajuda apenas em exemplos familiares. Os resultados levantam preocupações sobre a confiabilidade desses modelos quando enfrentam imagens desconhecidas em tarefas do mundo real.
Quando os humanos desenvolvem uma compreensão profunda de um domínio, como a gravidade ou outros princípios físicos básicos, ultrapassamos exemplos específicos para entender as abstrações subjacentes. Isso nos permite aplicar esse conhecimento de forma criativa em diferentes contextos e reconhecer novas instâncias, mesmo aquelas que nunca vimos antes, identificando o princípio em ação.
Quando um domínio é suficientemente importante, podemos até começar a percebê-lo onde ele não existe, como ocorre com a pareidolia, impulsionada pelo alto custo de não reconhecer uma instância real. Esse mecanismo de sobrevivência voltado para o reconhecimento de padrões é tão forte que nos leva a encontrar uma gama mais ampla de padrões onde não existem.
Quanto mais cedo e repetidamente um domínio é incutido em nós, mais profunda sua fundamentação e persistência ao longo da vida; e um dos primeiros conjuntos de dados visuais a que somos expostos na infância vem na forma de relógios de ensino, onde materiais impressos ou relógios analógicos interativos são usados para nos ensinar a dizer as horas:

Materiais de ensino para ajudar crianças a aprender a dizer as horas. Fonte: https://www.youtube.com/watch?v=IBBQXBhSNUs
Apesar de mudanças na moda de design de relógios muitas vezes nos desafiarem, a resiliência dessa primeira maestria de domínio é bastante impressionante, permitindo que discernamos os mostradores dos relógios analógicos mesmo diante de escolhas de design complexas ou ‘excêntricas’:

Alguns mostradores desafiadores na moda de relógios. Fonte: https://www.ablogtowatch.com/wait-a-minute-legibility-is-the-most-important-part-of-watch-design/
Os humanos não precisam de milhares de exemplos para aprender como os relógios funcionam; uma vez que o conceito básico é compreendido, podemos reconhecê-lo em quase qualquer forma, mesmo quando distorcido ou abstraído.
A dificuldade que os modelos de IA enfrentam com essa tarefa, em contraste, destaca uma questão mais profunda: sua aparente força pode depender mais da exposição em grande volume do que da compreensão.
Além do Jogo da Imitação?
A tensão entre desempenho superficial e ‘compreensão’ genuína surgiu repetidamente em investigações recentes sobre grandes modelos. No mês passado, a Universidade Zhejiang e a Universidade Westlake reformularam a questão em um artigo intitulado Os LLMs de nível PhD realmente compreendem a adição elementar? (não é o foco deste artigo), concluindo:
‘Apesar dos benchmarks impressionantes, os modelos mostram uma crítica dependência da correspondência de padrões, ao invés de verdadeira compreensão, evidenciada por falhas com representações simbólicas e violações de propriedades básicas.’
‘A provisão de regras explícitas prejudicando o desempenho sugere restrições arquitetônicas inerentes. Essas percepções revelam lacunas de avaliação e destacam a necessidade de arquiteturas capazes de raciocínio matemático genuíno além do reconhecimento de padrões.’
Essa semana a questão surge novamente, agora em uma colaboração entre a Universidade de Aeronáutica e Astronáutica de Nanjing e a Universidad Politécnica de Madrid na Espanha. Intitulado Os Modelos de Linguagem Multimodal (MLLMs) realmente aprenderam a dizer as horas em relógios analógicos?, o novo artigo explora como os modelos multimodais entendem a contagem do tempo.
Embora o progresso da pesquisa seja coberto apenas em termos amplos no artigo, os testes iniciais dos pesquisadores estabeleceram que o modelo de linguagem multimodal GPT-4.1 da OpenAI teve dificuldades em ler corretamente a hora a partir de um conjunto diversificado de imagens de relógios, muitas vezes fornecendo respostas incorretas mesmo em casos simples.
Isso aponta para uma possível lacuna nos dados de treinamento do modelo, levantando a necessidade de um conjunto de dados mais equilibrado, para testar se o modelo pode realmente aprender o conceito subjacente. Portanto, os autores criaram um conjunto de dados sintético de relógios analógicos, cobrindo de maneira uniforme todos os horários possíveis e evitando os preconceitos habituais encontrados em imagens da internet:
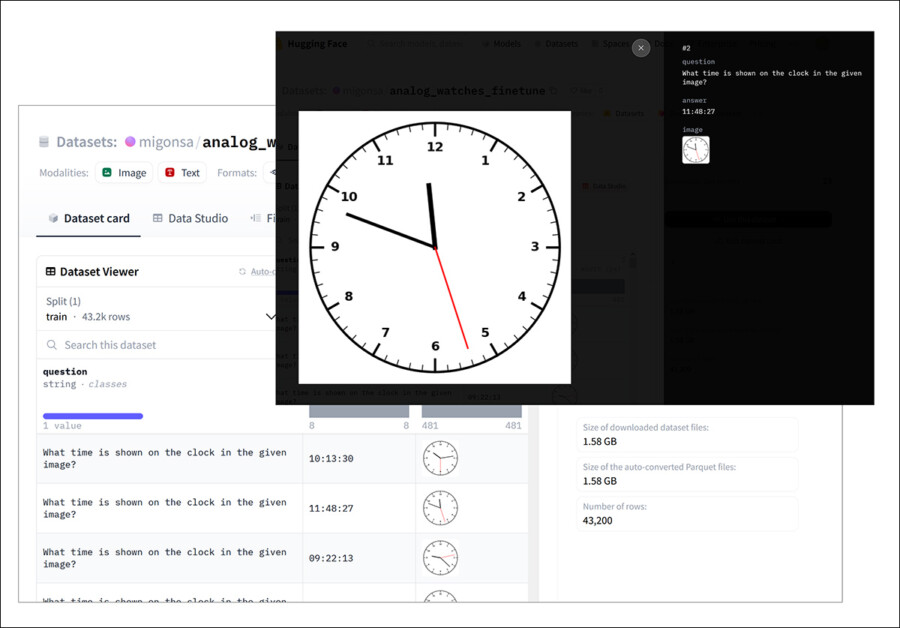
Um exemplo do conjunto de dados sintético de relógios analógicos dos pesquisadores, usado para ajustar um modelo GPT no novo trabalho. Fonte: https://huggingface.co/datasets/migonsa/analog_watches_finetune
Antes do ajuste fino no novo conjunto de dados, o GPT-4.1 falhou consistentemente em ler esses relógios. Após algum tempo de exposição à nova coleção, no entanto, seu desempenho melhorou – mas apenas quando as novas imagens se pareciam com aquelas que já havia visto.
Quando a forma do relógio ou o estilo dos ponteiros mudou, a precisão caiu drasticamente; mesmo pequenas alterações, como ponteiros mais finos ou com setas (imagem mais à direita abaixo), foram suficientes para provocá-lo; e o GPT-4.1 também teve dificuldades em interpretar os ‘relógios derretidos’ de Dali:
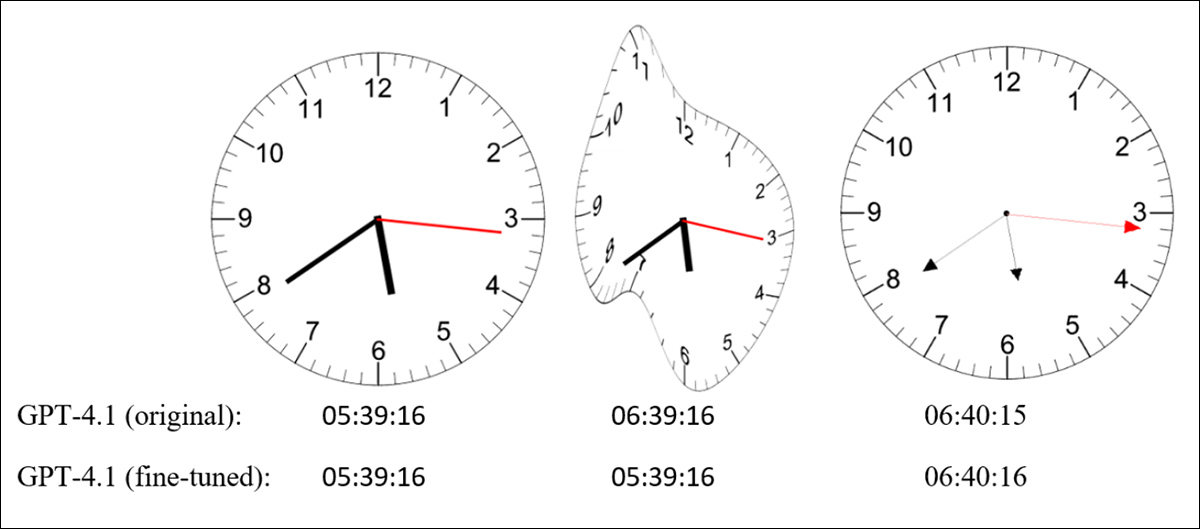
Imagens de relógios com design padrão (esquerda), forma distorcida (meio) e ponteiros modificados (direita), ao lado dos horários fornecidos pelo GPT-4.1 antes e depois do ajuste fino. Fonte: https://arxiv.org/pdf/2505.10862
Os autores deduzem que modelos atuais, como o GPT-4.1, podem estar aprendendo a ler relógios principalmente através de correspondência de padrões visuais, em vez de qualquer compreensão mais profunda do tempo, afirmando:
‘[GPT 4.1] falha quando o relógio é deformado ou quando os ponteiros são alterados para serem mais finos e terem uma seta. O Erro Absoluto Médio (MAE) na estimativa do tempo sobre 150 horários aleatórios foi de 232,48s para os relógios iniciais, 1380,69s quando a forma é deformada e 3726,93s quando os ponteiros são alterados.’
‘Esses resultados sugerem que o MLLM não aprendeu a dizer as horas, mas sim memorizou padrões.’
Tempo Suficiente
A maioria dos conjuntos de dados de treinamento depende de imagens coletadas da web, que tendem a repetir certos horários – especialmente 10:10, uma configuração popular em anúncios de relógios:

Do novo artigo, um exemplo da prevalência do horário ‘dez e dez’ em imagens de relógios analógicos.
Como resultado dessa gama limitada de horários representados, o modelo pode ver apenas uma faixa estreita de configurações de relógios possíveis, limitando sua capacidade de generalizar além desses padrões repetitivos.
Quanto ao porquê dos modelos falharem em interpretar corretamente os relógios distorcidos, o artigo afirma:
‘Embora o GPT-4.1 tenha um desempenho excepcional com imagens de relógios padrão, surpreende que a modificação dos ponteiros do relógio ao torná-los mais finos e adicionar setas leva a uma queda significativa em sua precisão.’
‘Intuitivamente, pode-se esperar que a mudança visual mais complexa – um mostrador distorcido – tenha um impacto maior no desempenho, no entanto, essa modificação parece ter um efeito relativamente menor.’
‘Isso levanta a pergunta: como os MLLMs interpretam relógios, e por que falham? Uma possibilidade é que ponteiros mais finos prejudiquem a capacidade do modelo de perceber direção, enfraquecendo sua compreensão da orientação espacial.’
‘Alternativamente, podem haver outros fatores que causam confusão quando o modelo tenta combinar os ponteiros de hora, minuto e segundo em uma leitura de tempo precisa.’
Os autores sustentam que identificar a causa raiz dessas falhas é crucial para avançar os modelos multimodais: se a questão reside em como o modelo percebe a direção espacial, o ajuste fino pode oferecer uma solução simples; mas se o problema decorre de uma dificuldade mais ampla em integrar múltiplos sinais visuais, isso aponta para uma fraqueza mais fundamental em como esses sistemas processam informações.
Testes de Ajuste Fino
Para testar se as falhas do modelo poderiam ser superadas com exposição, o GPT-4.1 foi aprimorado no mencionado e abrangente conjunto de dados sintético. Antes do ajuste fino, suas previsões estavam amplamente espalhadas, com erros significativos em todos os tipos de relógios. Após o ajuste fino na coleção, a precisão melhorou drasticamente em mostradores de relógios padrão e, em menor grau, nos distorcidos.
No entanto, relógios com ponteiros modificados, como formas mais finas ou setas, continuaram a produzir grandes erros.
Duas modos de falha distintos emergiram: em relógios normais e distorcidos, o modelo geralmente julgou incorretamente a direção dos ponteiros; mas em relógios com estilos de ponteiro alterados, frequentemente confundiu a função de cada ponteiro, confundindo hora com minuto ou minuto com segundo.
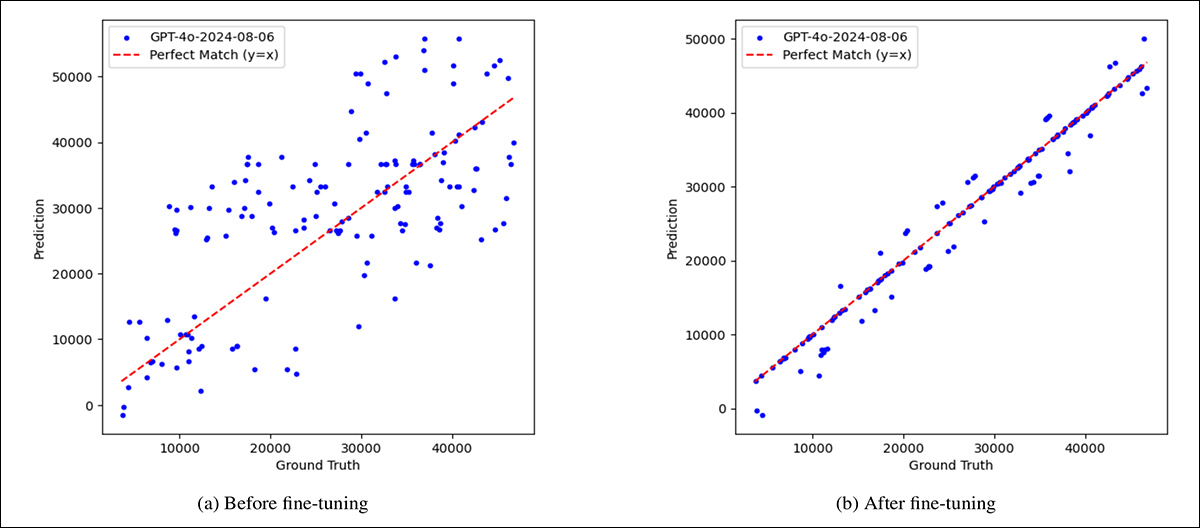
Uma comparação ilustrando a fraqueza inicial do modelo, e os ganhos parciais obtidos através do ajuste fino, mostrando tempo previsto versus real, em segundos, para 150 relógios aleatórios. À esquerda, antes do ajuste fino, as previsões do GPT-4.1 estão dispersas e frequentemente longe dos valores corretos, indicados pela linha diagonal vermelha. À direita, após o ajuste fino em um conjunto de dados sintético equilibrado, as previsões estão muito mais próximas da verdade, embora alguns erros persistam.
Isso sugere que o modelo aprendeu a associar características visuais como a espessura dos ponteiros com papéis específicos e teve dificuldades quando essas dicas mudaram.
A melhoria limitada em designs não familiares levanta ainda mais dúvidas sobre se um modelo desse tipo aprende o conceito abstrato de dizer as horas, ou simplesmente refina sua correspondência de padrões.
Sinais de Ponteiro
Assim, embora o ajuste fino tenha melhorado o desempenho do GPT-4.1 em relógios analógicos convencionais, ele teve muito menos impacto em relógios com ponteiros mais finos ou formatos de setas, levantando a possibilidade de que as falhas do modelo derivam menos do raciocínio abstrato e mais da confusão sobre qual ponteiro é qual.
Para testar se a precisão poderia melhorar se essa confusão fosse removida, uma nova análise foi conduzida nas previsões do modelo para o conjunto de dados ‘modificado-mão’. As saídas foram divididas em dois grupos: casos onde o GPT-4.1 reconheceu corretamente os ponteiros das horas, minutos e segundos; e casos em que não o fez.
As previsões foram avaliadas para Erro Absoluto Médio (MAE) antes e depois do ajuste fino, e os resultados foram comparados com os de relógios padrão; o erro angular também foi medido para cada ponteiro usando a posição do mostrador como linha de base:

Comparação de erro para relógios com e sem confusão de função dos ponteiros no conjunto de dados de mãos modificadas antes e depois do ajuste fino.
Confundir os papéis dos ponteiros do relógio levou aos maiores erros. Quando o GPT-4.1 confundiu o ponteiro das horas com o ponteiro dos minutos ou vice-versa, as estimativas de tempo resultantes estavam frequentemente muito erradas. Em contraste, os erros causados por julgar incorretamente a direção de um ponteiro identificado corretamente eram menores. Entre os três ponteiros, o ponteiro das horas mostrou o maior erro angular antes do ajuste fino, enquanto o ponteiro dos segundos apresentou o menor.
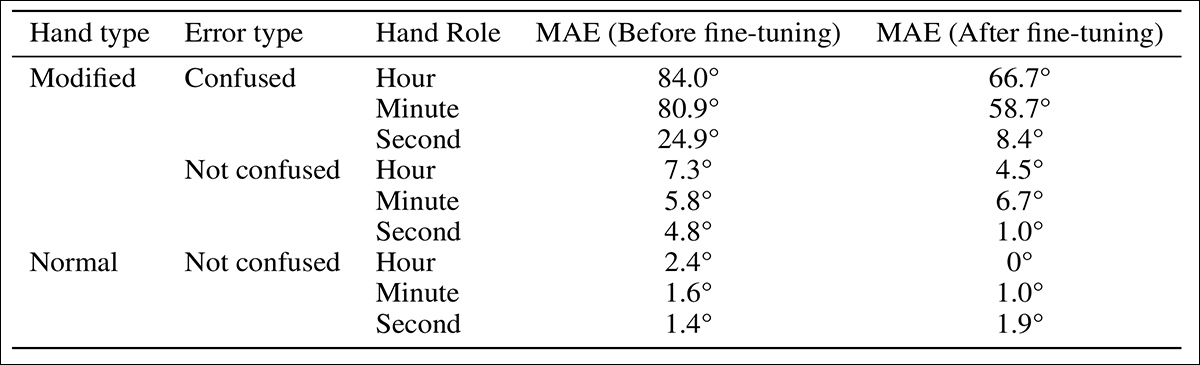
Erro angular por tipo de ponteiro para previsões com e sem confusão de função dos ponteiros, antes e depois do ajuste fino, no conjunto de dados de mãos modificadas.
Para focar apenas em erros direcionais, a análise foi limitada a casos onde o modelo reconheceu corretamente a função de cada ponteiro. Se o modelo tivesse internalizado um conceito geral de dizer as horas, seu desempenho nesses exemplos deveria ter correspondido à sua precisão em relógios padrão. Não ocorreu, e a precisão permaneceu visivelmente inferior.
Para investigar se a forma do ponteiro interferia na percepção direcional do modelo, foi realizado um segundo experimento: dois conjuntos de dados novos foram criados, cada um contendo sessenta relógios sintéticos com apenas um ponteiro das horas, apontando para uma marca de minuto diferente. Um conjunto usou o design original do ponteiro, e o outro a versão alterada. O modelo foi solicitado a nomear a marca de ticks que o ponteiro estava apontando.
Os resultados mostraram uma leve queda na precisão com os ponteiros modificados, mas não o suficiente para explicar as falhas mais amplas do modelo. Uma única característica visual desconhecida parecia capaz de perturbar a interpretação geral do modelo, mesmo em tarefas que havia realizado anteriormente com sucesso.
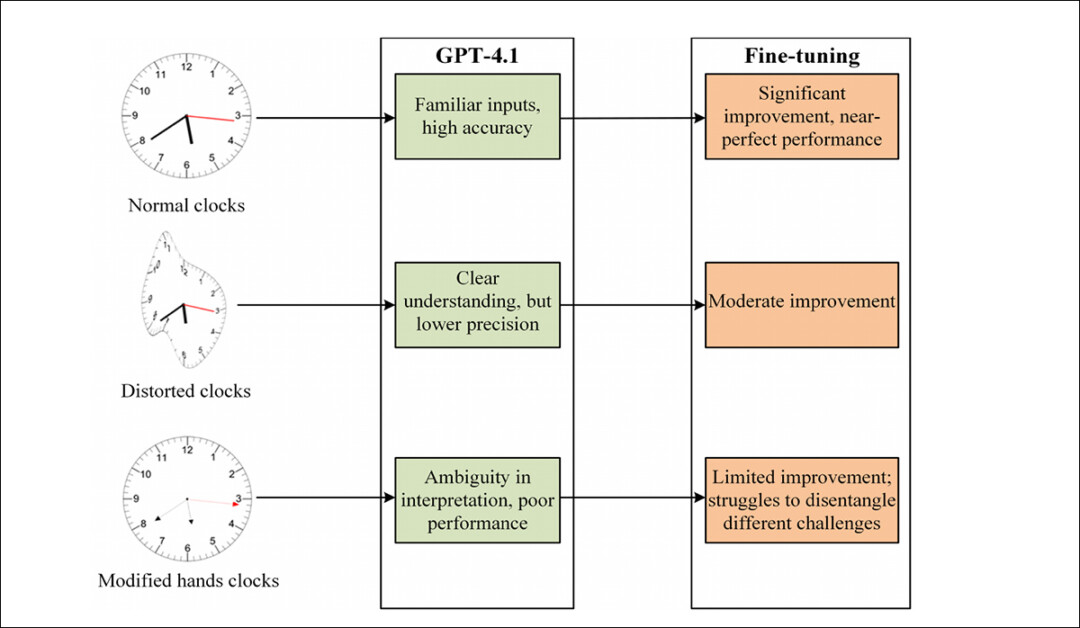
Visão geral do desempenho do GPT-4.1 antes e depois do ajuste fino em mostradores de relógios padrão, distorcidos e de mãos modificadas, destacando ganhos desiguais e fraquezas persistentes.
Conclusão
Embora o foco do artigo possa parecer trivial à primeira vista, não importa se os modelos de visão-linguagem alguma vez aprendem a ler relógios analógicos com 100% de precisão. O que confere peso ao trabalho é seu foco em uma questão mais profunda e recorrente: se saturar modelos com mais (e mais diversos) dados pode levar ao tipo de compreensão de domínio que os humanos adquirem por meio de abstração e generalização; ou se o único caminho viável é inundar o domínio com exemplos suficientes para antecipar cada variação provável na inferência.
Cada rota levanta dúvidas sobre o que as arquiteturas atuais realmente são capazes de aprender.
Publicada pela primeira vez na segunda-feira, 19 de maio de 2025

Conteúdo relacionado

A Microsoft acaba de ensinar seus agentes de IA a se comunicarem entre si—e isso pode transformar a maneira como trabalhamos.
[the_ad id="145565"] Participe de nossos boletins diários e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA de liderança na indústria. Saiba…

Google lança aplicativo autônomo NotebookLM para Android
[the_ad id="145565"] O Google lançou oficialmente o aplicativo NotebookLM para Android, um dia antes do Google I/O 2025 e conforme anunciado pela empresa. Desde seu lançamento…

Veja, Pense, Explique: A Ascensão dos Modelos de Língua Visuais na IA
[the_ad id="145565"] Sure! Here’s the content rewritten in Portuguese while retaining the HTML tags: <div id="mvp-content-main"><p>Há cerca de uma década, a…