


Como os geradores de imagens por IA concebem o passado? Novas pesquisas indicam que eles inserem smartphones no século XVIII, laptops em cenas da década de 1930 e aspiradores de pó em lares do século XIX, levantando questões sobre como esses modelos imaginam a história – e se são capazes de apresentar precisão histórica contextual de fato.
No início de 2024, as capacidades de geração de imagens do modelo multimodal de IA Gemini, do Google, foram criticadas por impor equidade demográfica em contextos inadequados, como ao gerar soldados alemães da WWII com proveniência improvável:

Pessoal militar alemão demograficamente improvável, conforme imaginado pelo modelo multimodal Gemini do Google em 2024. Fonte: Gemini AI/Google via The Guardian
Este foi um exemplo em que os esforços para corrigir viés em modelos de IA falharam ao não considerar o contexto histórico. Neste caso, a questão foi resolvida logo depois. No entanto, modelos baseados em difusão continuam propensos a gerar versões da história que confundem aspectos e artefatos modernos e históricos.
Isso se deve em parte ao entrelaçamento, onde qualidades que frequentemente aparecem juntas nos dados de treinamento se fundem na saída do modelo. Por exemplo, se objetos modernos, como smartphones, costumam co-ocorrer com a ação de falar ou ouvir no conjunto de dados, o modelo pode aprender a associar essas atividades a dispositivos modernos, mesmo quando o prompt especifica um cenário histórico. Uma vez que essas associações estão incorporadas nas representações internas do modelo, torna-se difícil separar a atividade de seu contexto contemporâneo, levando a resultados historicamente imprecisos.
Um novo artigo da Suíça, que examina o fenômeno das gerações históricas entrelaçadas em modelos de difusão latente, observa que estruturas de IA que são muito capazes de criar pessoas fotorealistas ainda assim preferem retratar figuras históricas de maneiras históricas:
![Do novo artigo, representações diversas via LDM do prompt 'Uma imagem fotorealista de uma pessoa rindo com um amigo no [período histórico]', com cada período indicado em cada saída. Como podemos ver, o meio da era se tornou associado ao conteúdo. Fonte: https://arxiv.org/pdf/2505.17064](https://11o.info/wp-content/uploads/2025/05/1748270099_621_Como-Impedir-que-a-IA-Retrate-iPhones-em-Epocas-Passadas.jpg)
Do novo artigo, representações diversas via LDM do prompt ‘Uma imagem fotorealista de uma pessoa rindo com um amigo no [período histórico]’, com cada período indicado em cada saída. Como podemos ver, o meio da era se tornou associado ao conteúdo. Fonte: https://arxiv.org/pdf/2505.17064
Para o prompt ‘Uma imagem fotorealista de uma pessoa rindo com um amigo no [período histórico]’, um dos três modelos testados frequentemente ignora o prompt negativo ‘monocromático’ e em vez disso utiliza tratamentos de cor que refletem os meios visuais da era especificada, como imitar os tons suaves do filme em celulóide das décadas de 1950 e 1970.
Ao testar os três modelos em sua capacidade de criar anacronismos (coisas que não pertencem ao período-alvo, ou ‘fora do tempo’ – que podem ser do futuro do período-alvo, assim como de seu passado), eles encontraram uma tendência geral para confundir atividades atemporais (como ‘cantar’ ou ‘cozinhar’) com contextos e equipamentos modernos:

Atividades diversas que são perfeitamente válidas para séculos anteriores são retratadas com tecnologia e equipamentos atuais ou mais recentes, contra o espírito da imagem solicitada.
Vale ressaltar que smartphones são particularmente difíceis de separar do idioma da fotografia e de muitos outros contextos históricos, uma vez que sua proliferação e representação estão bem documentadas em conjuntos de dados hiperscala influentes, como o Common Crawl:

No modelo generativo de texto para imagem Flux, comunicações e smartphones são conceitos intimamente associados – mesmo quando o contexto histórico não permite.
Para determinar a extensão do problema, e para oferecer às futuras pesquisas um caminho a seguir com esse desafio particular, os autores do novo artigo desenvolveram um conjunto de dados sob medida contra o qual testar sistemas generativos. Em breve, veremos esse novo trabalho, intitulado História Sintética: Avaliando Representações Visuais do Passado em Modelos de Difusão, produzido por dois pesquisadores da Universidade de Zurique. O conjunto de dados e o código estão disponíveis publicamente.
Uma ‘Verdade’ Frágil
Alguns dos temas no artigo tocam em questões culturalmente sensíveis, como a sub-representação de raças e gênero em representações históricas. Enquanto a imposição de igualdade racial pelo Gemini na grossamente desigual Terceiro Reich é uma revisão histórica absurda e insultante, restaurar as representações raciais ‘tradicionais’ (onde modelos de difusão ‘atualizaram’ essas) geralmente efetivamente ‘re-branqueiam’ a história.
Recentes shows históricos de sucesso, como Bridgerton, borram a precisão demográfica histórica de maneiras que provavelmente influenciarão futuros conjuntos de dados de treinamento, complicando os esforços para alinhar imagens de época geradas por LLM com padrões tradicionais. No entanto, este é um tópico complexo, dada a tendência histórica da história (ocidental) em favorecer riqueza e branquitude, e deixar tantas ‘histórias menores’ não contadas.
Levando em conta esses parâmetros culturais complicados e em constante mudança, vamos dar uma olhada na nova abordagem dos pesquisadores.
Método e Testes
Para testar como os modelos generativos interpretam o contexto histórico, os autores criaram HistVis, um conjunto de dados de 30.000 imagens produzidas a partir de cem prompts que retratam atividades humanas comuns, cada uma renderizada em dez períodos de tempo distintos:
Um exemplo do conjunto de dados HistVis, que os autores disponibilizaram no Hugging Face. Fonte: https://huggingface.co/datasets/latentcanon/HistVis
As atividades, como cozinhar, rezar ou ouvir música, foram escolhidas por sua universalidade, e formuladas em um formato neutro para evitar ancorar o modelo em um determinado estilo estético. Os períodos de tempo do conjunto de dados variam do século XVII até os dias atuais, com foco adicional em cinco décadas individuais do século XX.
Trinta mil imagens foram geradas usando três modelos de difusão amplamente utilizados e de código aberto: Stable Diffusion XL; Stable Diffusion 3; e FLUX.1. Ao isolar o período de tempo como a única variável, os pesquisadores criaram uma base estruturada para avaliar como sinais históricos são visualmente codificados ou ignorados por esses sistemas.
Dominância de Estilo Visual
Os autores inicialmente examinaram se os modelos generativos costumam adotar estilos visuais específicos ao retratar períodos históricos; pois parecia que mesmo quando os prompts não incluíam menção a meio ou estética, os modelos frequentemente associariam séculos específicos a estilos característicos:
![Estilos visuais previstos para imagens geradas a partir do prompt 'Uma pessoa dançando com outra no [período histórico]' (à esquerda) e do prompt modificado 'Uma imagem fotorealista de uma pessoa dançando com outra no [período histórico]' com 'imagem monocromática' definida como um prompt negativo (à direita).](https://11o.info/wp-content/uploads/2025/05/1748270100_93_Como-Impedir-que-a-IA-Retrate-iPhones-em-Epocas-Passadas.jpg)
Estilos visuais previstos para imagens geradas a partir do prompt ‘Uma pessoa dançando com outra no [período histórico]’ (à esquerda) e do prompt modificado ‘Uma imagem fotorealista de uma pessoa dançando com outra no [período histórico]’ com ‘imagem monocromática’ definida como um prompt negativo (à direita).
Para medir essa tendência, os autores treinaram uma rede neural convolucional (CNN) para classificar cada imagem no conjunto de dados HistVis em uma das cinco categorias: desenho; gravura; ilustração; pintura; ou fotografia. Essas categorias foram concebidas para refletir padrões comuns que emergem ao longo dos períodos, e que apoiam comparações estruturadas.
O classificador foi baseado em um modelo VGG16 pré-treinado no ImageNet e ajustado com 1.500 exemplos por classe de um conjunto de dados derivado do WikiArt. Como o WikiArt não distingue entre fotografia monocromática e colorida, um índice de colorido foi usado para rotular imagens de baixa saturação como monocromáticas.
O classificador treinado foi então aplicado ao conjunto completo de dados, com os resultados mostrando que todos os três modelos impõem padrões estilísticos consistentes por período: SDXL associa os séculos XVII e XVIII a gravuras, enquanto SD3 e FLUX.1 tendem à pintura. Nas décadas do século XX, SD3 favorece a fotografia monocromática, enquanto SDXL frequentemente retorna ilustrações modernas.
Essas preferências foram encontradas em persistência, apesar de ajustes em prompts, sugerindo que os modelos codificam ligações arraigadas entre estilo e contexto histórico.
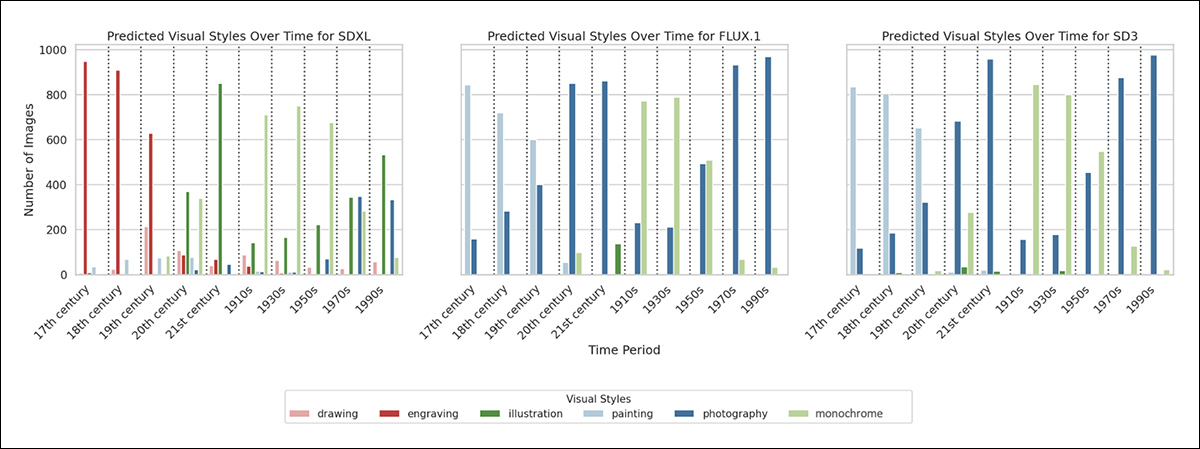
Estilos visuais previstos de imagens geradas por períodos históricos para cada modelo de difusão, com base em 1.000 amostras por período por modelo.
Para quantificar quão fortemente um modelo relaciona um período histórico a um determinado estilo visual, os autores desenvolveram uma métrica que chamam de Dominância de Estilo Visual (VSD). Para cada modelo e período de tempo, VSD é definido como a proporção de saídas previstas para compartilhar o estilo mais comum:
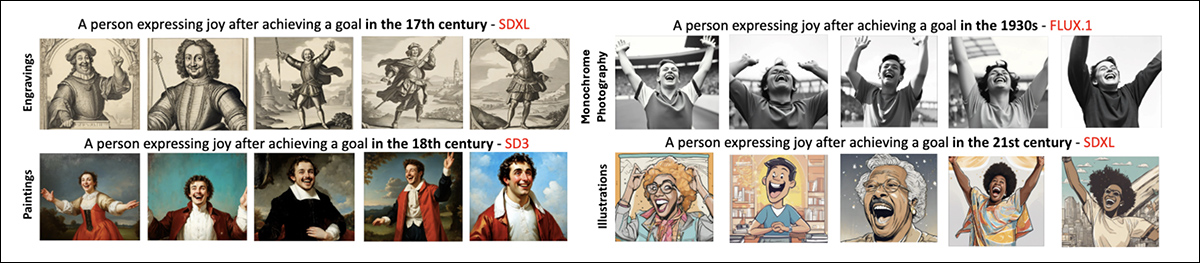
Exemplos de viés estético em todos os modelos.
Uma pontuação mais alta indica que um único estilo domina as saídas para aquele período, enquanto uma pontuação mais baixa aponta para maior variação. Isso permite comparar quão rigidamente cada modelo adere a convenções estilísticas específicas ao longo do tempo.
Aplicado ao conjunto completo de dados HistVis, a métrica VSD revela níveis diferentes de convergência, ajudando a esclarecer quão fortemente cada modelo restringe sua interpretação visual do passado:
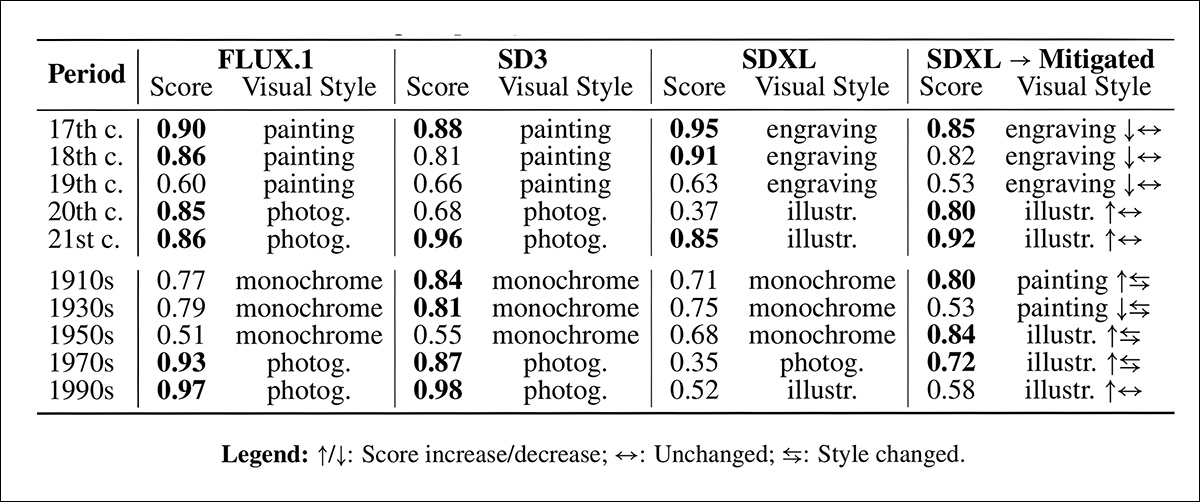
A tabela de resultados acima mostra as pontuações VSD ao longo dos períodos históricos para cada modelo. Nos séculos XVII e XVIII, o SDXL tende a produzir gravuras com alta consistência, enquanto SD3 e FLUX.1 favorecem a pintura. Já nos séculos XX e XXI, SD3 e FLUX.1 se voltam para a fotografia, enquanto SDXL apresenta mais variação, mas muitas vezes recorre a ilustrações.
Todos os três modelos demonstram uma forte preferência por imagens monocromáticas nas primeiras décadas do século XX, especialmente nas décadas de 1910, 1930 e 1950.
Para testar se esses padrões poderiam ser mitigados, os autores utilizaram engenharia de prompt, solicitando explicitamente fotorealismo e desestimulando a saída monocromática usando um prompt negativo. Em alguns casos, as pontuações de dominância diminuíram, e o estilo predominante mudou, por exemplo, de monocromático para pintura, nos séculos XVII e XVIII.
No entanto, essas intervenções raramente produziram imagens genuinamente fotorealistas, indicando que os padrões estilísticos dos modelos estão profundamente arraigados.
Consistência Histórica
A próxima linha de análise observou a consistência histórica: se as imagens geradas incluíam objetos que não se encaixavam no período de tempo. Em vez de usar uma lista fixa de itens proibidos, os autores desenvolveram um método flexível que utilizou grandes modelos de linguagem (LLMs) e modelos de visão-linguagem (VLMs) para identificar elementos que parecessem fora de lugar, com base no contexto histórico.
O método de detecção seguiu o mesmo formato que o conjunto de dados HistVis, onde cada prompt combinava um período histórico com uma atividade humana. Para cada prompt, o GPT-4o gerou uma lista de objetos que seriam inadequados ao período especificado; e para cada objeto proposto, GPT-4o produziu uma pergunta de sim ou não projetada para verificar se aquele objeto aparecia na imagem gerada.
Por exemplo, dado o prompt ‘Uma pessoa ouvindo música no século XVIII’, GPT-4o poderia identificar dispositivos de áudio modernos como historicamente imprecisos e gerar a pergunta: ‘A pessoa está usando fones de ouvido ou um smartphone que não existiu no século XVIII?’.
Essas perguntas foram reenviadas para o GPT-4o em uma configuração de perguntas e respostas visuais, onde o modelo revisou a imagem e retornou uma resposta de sim ou não para cada uma. Esse fluxo de trabalho permitiu a detecção de conteúdo historicamente implausível sem depender de nenhuma taxonomia pré-definida de objetos modernos:

Exemplos de imagens geradas sinalizadas pelo método de detecção em duas etapas, mostrando elementos anacrônicos: fones de ouvido no século XVIII; um aspirador de pó no século XIX; um laptop na década de 1930; e um smartphone na década de 1950.
Para medir com que frequência anacronismos apareciam nas imagens geradas, os autores introduziram um método simples para pontuar frequência e severidade. Primeiro, eles consideraram pequenas diferenças de redação em como o GPT-4o descreveu o mesmo objeto.
Por exemplo, dispositivos de áudio modernos e dispositivos de áudio digitais foram tratados como equivalentes. Para evitar a contagem dupla, foi utilizado um sistema de correspondência difusa para agrupar essas variações superficiais sem afetar conceitos genuinamente distintos.
Uma vez que todos os anacronismos propostos foram normalizados, duas métricas foram computadas: frequência mediu com que frequência um determinado objeto apareceu em imagens para um período de tempo específico e modelo; e severidade mediu com que regularidade esse objeto apareceu uma vez que tinha sido sugerido pelo modelo.
Se um telefone moderno foi sinalizado dez vezes e apareceu em dez imagens geradas, ele recebeu uma pontuação de severidade de 1,0. Se apareceu apenas cinco vezes, a pontuação de severidade foi de 0,5. Essas pontuações ajudaram a identificar não apenas se anacronismos ocorreram, mas quão firmemente estavam embutidos na saída do modelo para cada período:
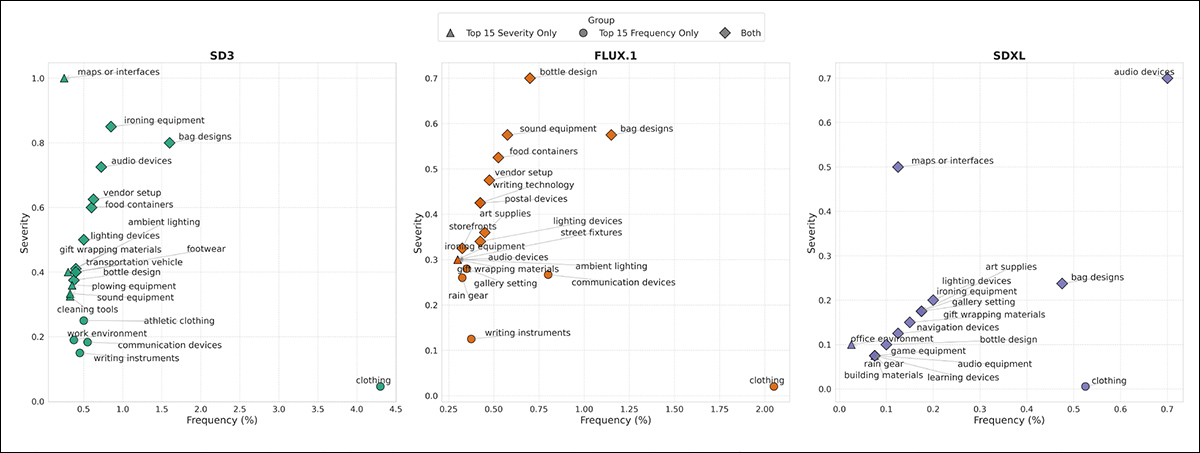
Quinze principais elementos anacrônicos para cada modelo, plotados por frequência no eixo x e severidade no eixo y. Círculos marcam elementos classificados entre os quinze principais por frequência, triângulos por severidade, e diamantes por ambos.
Aqui vemos os quinze anacronismos mais comuns para cada modelo, classificados pela frequência com que apareceram e pela consistência com que corresponderam aos prompts.
Roupas foram frequentes, mas dispersas, enquanto itens como dispositivos de áudio e equipamentos de passar roupa apareceram com menos frequência, mas com alta consistência – padrões que sugerem que os modelos frequentemente respondem à atividade no prompt mais do que ao período de tempo.
O SD3 apresentou a maior taxa de anacronismos, especialmente em imagens do século XIX e da década de 1930, seguido pelo FLUX.1 e SDXL.
Para testar quão bem o método de detecção correspondia ao julgamento humano, os autores conduziram um estudo com usuários apresentando 1.800 imagens amostradas aleatoriamente do SD3 (o modelo com a taxa mais alta de anacronismos), com cada imagem avaliada por três trabalhadores em massa. Após filtrar as respostas confiáveis, 2.040 julgamentos de 234 usuários foram incluídos, e o método concordou com a maioria dos votos em 72 por cento dos casos.
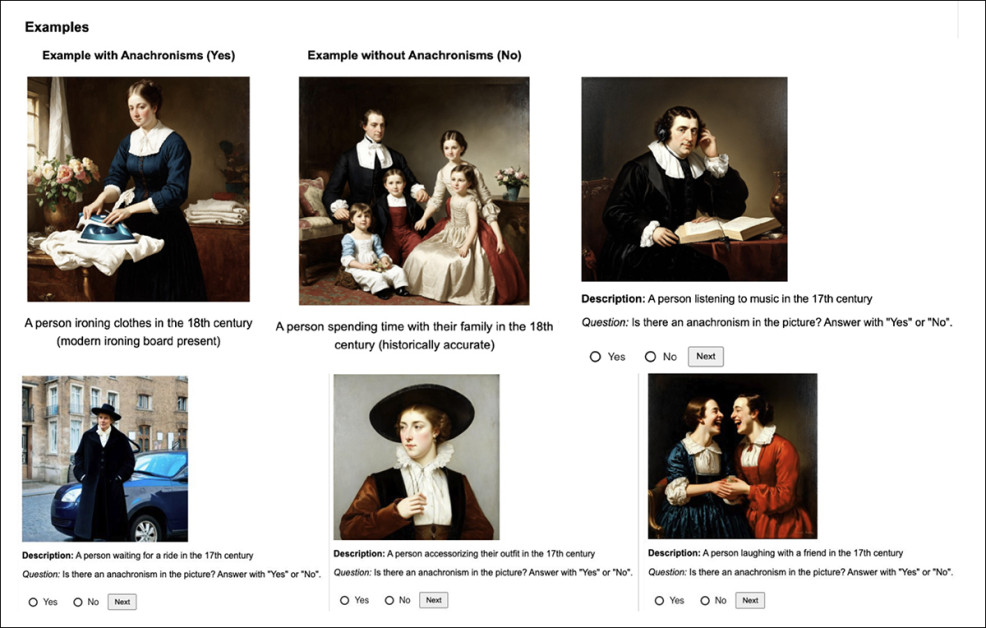
GUI para o estudo de avaliação humana, mostrando instruções da tarefa, exemplos de imagens precisas e anacrônicas, e perguntas sim-não para identificar inconsistências temporais nas saídas geradas.
Demografia
A análise final examinou como os modelos retratam raça e gênero ao longo do tempo. Usando o conjunto de dados HistVis, os autores compararam as saídas dos modelos com estimativas de referência geradas por um modelo de linguagem. Essas estimativas não eram precisas, mas ofereciam uma noção aproximada de plausibilidade histórica, ajudando a revelar se os modelos adaptavam representações ao período pretendido.
Para avaliar essas representações em larga escala, os autores construíram um pipeline comparando a demografia gerada pelos modelos com as expectativas aproximadas para cada tempo e atividade. Eles primeiro usaram o classificador FairFace, uma ferramenta baseada em ResNet34 treinada com mais de cem mil imagens, para detectar gênero e raça nas saídas geradas, permitindo a medição de com que frequência rostos em cada cena foram classificados como masculinos ou femininos, e possibilitando o rastreamento de categorias raciais ao longo dos períodos.

Exemplos de imagens geradas mostrando sobre-representação demográfica em diferentes modelos, períodos e atividades.
Resultados de baixa confiança foram filtrados para reduzir ruídos, e previsões foram médias sobre todas as imagens ligadas a um tempo e atividade específicos. Para verificar a confiabilidade das leituras do FairFace, um segundo sistema baseado em DeepFace foi usado em uma amostra de 5.000 imagens. Os dois classificadores demonstraram forte concordância, apoiando a consistência das leituras demográficas utilizadas no estudo.
Para comparar as saídas dos modelos com a plausibilidade histórica, os autores pediram ao GPT-4o para estimar a distribuição esperada de gênero e raça para cada atividade e período de tempo. Essas estimativas serviram como referências aproximadas em vez de verdade absoluta. Duas métricas foram então utilizadas: sub-representação e sobre-representação, medindo quão longe as saídas do modelo se desviaram das expectativas do LLM.
Os resultados mostraram padrões claros: o FLUX.1 muitas vezes super-representava homens, mesmo em cenários como cozinhar, onde se esperava mulheres; SD3 e SDXL mostraram tendências semelhantes em categorias como trabalho, educação e religião; rostos brancos apareceram mais do que o esperado de maneira geral, embora esse viés tenha diminuído em períodos mais recentes; e algumas categorias mostraram picos inesperados na representação não-branca, sugerindo que o comportamento do modelo pode refletir correlações do conjunto de dados em vez do contexto histórico:
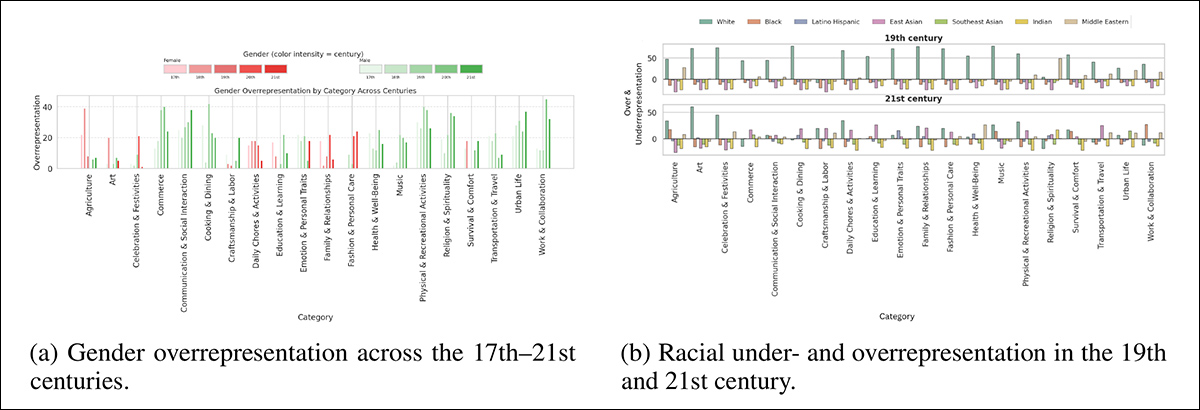
Sobre-representação e sub-representação de gênero e raça nas saídas do FLUX.1 ao longo dos séculos e atividades, mostradas como diferenças absolutas das estimativas demográficas do GPT-4o.
Os autores concluem:
‘Nossa análise revela que os modelos de [Texto-para-imagem/TTI] dependem de codificações estilísticas limitadas, em vez de entendimentos nuançados dos períodos históricos. Cada era está fortemente ligada a um estilo visual específico, resultando em retratos unidimensionais da história.
‘Notavelmente, representações fotorealistas de pessoas aparecem apenas a partir do século XX, com apenas raras exceções no FLUX.1 e SD3, sugerindo que os modelos reforçam associações aprendidas em vez de se adaptar de maneira flexível aos contextos históricos, perpetuando a noção de que o realismo é uma característica moderna.
‘Além disso, anacronismos frequentes sugerem que os períodos históricos não são separadamente definidos nos espaços latentes desses modelos, uma vez que artefatos modernos frequentemente emergem em configurações pré-modernas, minando a confiabilidade dos sistemas de TTI em contextos educacionais e de patrimônio cultural.’
Conclusão
Durante o treinamento de um modelo de difusão, novos conceitos não se acomodam de maneira ordenada em slots pré-definidos dentro do espaço latente. Em vez disso, eles formam clusters moldados pela frequência com que aparecem e por sua proximidade a ideias relacionadas. O resultado é uma estrutura vagamente organizada onde os conceitos existem em relação à sua frequência e contexto típico, em vez de por qualquer separação limpa ou empírica.
Isso torna difícil isolar o que conta como ‘histórico’ dentro de um grande conjunto de dados de uso geral. Como as descobertas do novo artigo sugerem, muitos períodos de tempo são representados mais pela aparência dos meios usados para descrevê-los do que por qualquer detalhe histórico mais profundo.
Essa é uma das razões pelas quais continua sendo difícil gerar uma imagem fotorealista de qualidade 2025 de um personagem da (por exemplo) século XIX; na maioria dos casos, o modelo dependerá de tropos visuais retirados de filmes e televisão. Quando esses falham em corresponder ao pedido, há pouco mais nos dados para compensar. Superar essa lacuna provavelmente dependerá de melhorias futuras na desacoplagem de conceitos sobrepostos.
Publicado pela primeira vez na segunda-feira, 26 de maio de 2025

Conteúdo relacionado
Nvidia supera as estimativas para os resultados do 1º trimestre com aumento de 69% na receita em comparação ao ano passado
[the_ad id="145565"] A Nvidia, a empresa de chips de inteligência artificial e gráficos que está impulsionando mudanças sociais com a IA, relatou que a receita do primeiro…

Competir com um incumbente, com Linear Cristina Cordova no Sessions: AI
[the_ad id="145565"] Um problema familiar está enfrentando novos entrantes na indústria de IA: Como se destacar quando os incumbentes estão tão enraizados? Essa é apenas uma…

CEO da Nvidia critica a política dos EUA que impede vendas de chips de IA para a China.
[the_ad id="145565"] O CEO da Nvidia, Jensen Huang, adentrou o mundo da política com um comentário criticando a política dos EUA que cortou as vendas de seus chips para a…