


Participe das nossas newsletters diárias e semanais para as últimas atualizações e conteúdo exclusivo sobre cobertura de IA de ponta. Saiba Mais
A baleia retornou.
Após agitar a comunidade global de IA e negócios no início deste ano com o lançamento inicial do seu aclamado modelo de IA de raciocínio open source R1 em 20 de janeiro, a startup chinesa DeepSeek — um desdobramento da conhecida firma de análise quantitativa local High-Flyer Capital Management — lançou o DeepSeek-R1-0528, uma atualização significativa que traz o modelo gratuito e aberto da DeepSeek para perto da paridade em capacidades de raciocínio com modelos pagos proprietários como o o3 da OpenAI e o Google Gemini 2.5 Pro.
Essa atualização foi projetada para oferecer um desempenho mais robusto em tarefas complexas de raciocínio em matemática, ciência, negócios e programação, além de recursos aprimorados para desenvolvedores e pesquisadores.
Assim como seu predecessor, o DeepSeek-R1-0528 está disponível sob a permissiva e aberta Licença MIT, apoiando uso comercial e permitindo que os desenvolvedores personalizem o modelo para suas necessidades.
Os pesos do modelo open-source estão disponíveis através da comunidade de compartilhamento de código de IA Hugging Face, e documentação detalhada é fornecida para aqueles que desejam implementar localmente ou integrar via a API da DeepSeek.
Usuários existentes da API DeepSeek terão suas inferências de modelo atualizadas automaticamente para R1-0528 sem custo adicional. O custo atual da API da DeepSeek é de $0.14 por 1 milhão de tokens de entrada durante o horário regular de 8h30 às 12h30 (cai para $0.035 durante horários promocionais). A saída de 1 milhão de tokens é consistentemente precificada em $2.19.
Para aqueles que desejam executar o modelo localmente, a DeepSeek publicou instruções detalhadas em seu repositório do GitHub. A empresa também incentiva a comunidade a fornecer feedback e perguntas por meio de seu e-mail de serviço.
Usuários individuais podem experimentá-lo gratuitamente através do site da DeepSeek aqui, embora seja necessário fornecer um número de telefone ou acesso à conta do Google para se inscrever.
Raciocínio aprimorado e desempenho de benchmark
No cerne da atualização estão melhorias significativas na capacidade do modelo de lidar com tarefas desafiadoras de raciocínio.
A DeepSeek explica em seu novo cartão de modelo no HuggingFace que essas melhorias resultam da utilização de recursos computacionais aumentados e da aplicação de otimizações algorítmicas no pós-treinamento. Essa abordagem resultou em melhorias notáveis em vários benchmarks.
No teste AIME 2025, por exemplo, a precisão do DeepSeek-R1-0528 saltou de 70% para 87.5%, indicando processos de raciocínio mais profundos que agora têm uma média de 23.000 tokens por pergunta, comparados a 12.000 na versão anterior.
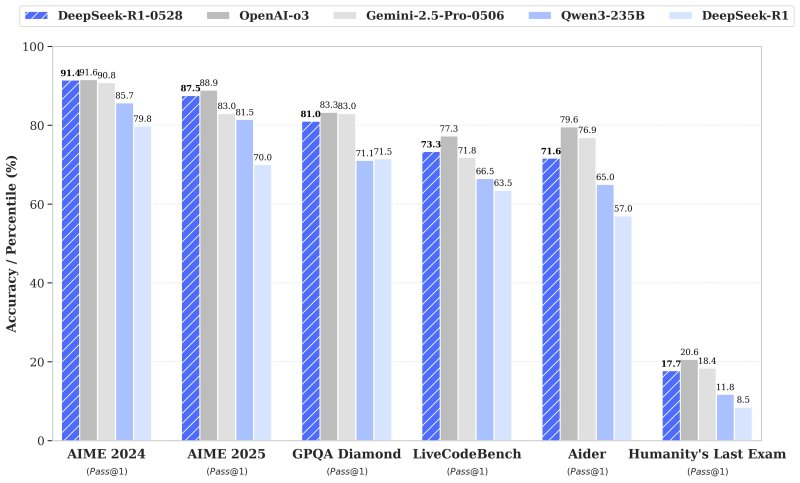
O desempenho em codificação também teve um aumento, com a precisão no conjunto de dados LiveCodeBench subindo de 63.5% para 73.3%. Na exigente “Última Prova da Humanidade”, o desempenho mais do que dobrou, alcançando 17.7% a partir de 8.5%.
Esses avanços colocam o DeepSeek-R1-0528 mais perto do desempenho de modelos estabelecidos como o o3 da OpenAI e o Gemini 2.5 Pro, de acordo com avaliações internas — esses modelos têm limites de taxa e/ou exigem assinaturas pagas para acesso.
Melhorias na experiência do usuário e novos recursos
Além das melhorias de desempenho, o DeepSeek-R1-0528 apresenta vários novos recursos destinados a aprimorar a experiência do usuário.
A atualização adiciona suporte para saída JSON e chamadas de função, recursos que devem facilitar para os desenvolvedores integrar as capacidades do modelo em suas aplicações e fluxos de trabalho.
As capacidades de front-end também foram refinadas, e a DeepSeek afirma que essas mudanças criarão uma interação mais suave e eficiente para os usuários.
Além disso, a taxa de alucinação do modelo foi reduzida, contribuindo para resultados mais confiáveis e consistentes.
Uma atualização notável é a introdução de prompts de sistema. Diferente da versão anterior, que exigia um token especial no início da saída para ativar o modo de “pensamento”, essa atualização remove essa necessidade, agilizando a implementação para os desenvolvedores.
Versões menores para aqueles com orçamentos computacionais limitados
Juntamente com este lançamento, a DeepSeek destilou seu raciocínio em cadeia em uma variante menor, o DeepSeek-R1-0528-Qwen3-8B, que deve ajudar aqueles tomadores de decisão e desenvolvedores empresariais que não têm o hardware necessário para executar o modelo completo.
Esta versão destilada supostamente alcança desempenho de ponta entre modelos open-source em tarefas como AIME 2024, superando o Qwen3-8B em 10% e igualando o Qwen3-235B-thinking.
De acordo com Modal, executar um modelo de linguagem grande (LLM) com 8 bilhões de parâmetros em precisão de meio (FP16) requer aproximadamente 16 GB de memória GPU, equivalente a cerca de 2 GB por bilhão de parâmetros.
Portanto, uma única GPU de alto desempenho com pelo menos 16 GB de VRAM, como a NVIDIA RTX 3090 ou 4090, é suficiente para executar um LLM de 8B em precisão FP16. Para modelos mais quantizados, GPUs com 8–12 GB de VRAM, como a RTX 3060, podem ser usadas.
A DeepSeek acredita que esse modelo destilado será útil para pesquisa acadêmica e aplicações industriais que requerem modelos de menor escala.
Reações iniciais de desenvolvedores e influenciadores de IA
A atualização já atraiu atenção e elogios de desenvolvedores e entusiastas nas redes sociais.
Haider, conhecido como “@slow_developer”, compartilhou no X que o DeepSeek-R1-0528 “é simplesmente incrível em codificação”, descrevendo como gerou código limpo e testes funcionais para um desafio de sistema de pontuação de palavras, ambos funcionando perfeitamente na primeira tentativa. Segundo ele, apenas o o3 havia conseguido igualar essa performance anteriormente.
Enquanto isso, Lisan al Gaib postou que “a DeepSeek está mirando no rei: o3 e Gemini 2.5 Pro”, refletindo o consenso de que a nova atualização aproxima o modelo da DeepSeek desses melhores desempenhos.
Outro influenciador de notícias e rumores de IA, Chubby, comentou que “a DeepSeek estava cozinhando!” e destacou como a nova versão está quase em paridade com o o3 e o Gemini 2.5 Pro.
Chubby até especulou que a última atualização do R1 pode indicar que a DeepSeek está se preparando para lançar seu aguardado e presumido modelo “R2” em breve.
Olhando para o futuro
A liberação do DeepSeek-R1-0528 ressalta o compromisso da DeepSeek em fornecer modelos open-source de alto desempenho que priorizam raciocínio e usabilidade. Ao combinar ganhos mensuráveis em benchmark com recursos práticos e uma licença open-source permissiva, o DeepSeek-R1-0528 está posicionado como uma ferramenta valiosa para desenvolvedores, pesquisadores e entusiastas que buscam aproveitar o que há de mais recente nas capacidades de modelos de linguagem.


Conteúdo relacionado

3 dias até a abertura das portas do TC Sessions: AI na UC Berkeley
[the_ad id="145565"] Daqui a três dias, o futuro da IA atravessará as portas do TechCrunch Sessions: AI no Zellerbach Hall da UC Berkeley. Na quinta-feira, 5 de junho, TC…

TC Sessions: Contagem Regressiva de Trivia sobre IA — Ganhe Ingressos Incríveis!
[the_ad id="145565"] Você acha que sabe qual IA venceu um campeão humano no jogo de Go? Ou qual empresa desenvolveu a arquitetura Transformer que alimenta muitos modelos de…

Faltam 5 dias para garantir sua mesa de expositor na TC All Stage | TechCrunch
[the_ad id="145565"] O tempo está se esgotando. As mesas de expositores para TechCrunch All Stage, que acontecerá no dia 15 de julho em Boston, estão quase esgotadas — e o…