


Ferramentas de IA conversacional, como o ChatGPT e o Google Gemini, estão sendo utilizadas para criar deepfakes que não trocam rostos, mas que, de maneira mais sutil, podem reescrever toda a narrativa de uma imagem. Ao alterar gestos, adereços e fundos, essas edições enganam tanto detetores de IA quanto humanos, aumentando a dificuldade de identificar o que é real online.
No clima atual, especialmente após legislações significativas como a Lei TAKE IT DOWN, muitos de nós associamos deepfakes e síntese de identidade impulsionada por IA com pornografia não consensual e manipulação política – em geral, distorções grosseiras da verdade.
Isso nos acostuma a esperar que imagens manipuladas por IA sempre visem conteúdos de alto impacto, onde a qualidade da renderização e a manipulação de contexto podem conseguir um golpe de credibilidade, ao menos no curto prazo.
No entanto, historicamente, alterações muito mais sutis têm muitas vezes um efeito mais sinistro e duradouro – como a engenhosa manobra fotográfica que permitiu a Stalin remover aqueles que caíram em desgraça do registro fotográfico, como satirizado no romance de George Orwell Mil Novecentos e Oitenta e Quatro, onde o protagonista Winston Smith passa seus dias reescrevendo a história e criando, destruindo e ’emendando’ fotos.
No exemplo a seguir, o problema da segunda imagem é que ‘não sabemos o que não sabemos’ – que o ex-chefe da polícia secreta de Stalin, Nikolai Yezhov, costumava ocupar o espaço onde agora só há uma barreira de segurança:

Agora você o vê, agora ele está…vapor. A manipulação fotográfica da era Stalin remove um membro do partido envergonhado da história. Fonte: Domínio público, via https://www.rferl.org/a/soviet-airbrushing-the-censors-who-scratched-out-history/29361426.html
Correntes desse tipo, frequentemente repetidas, persistem de muitas maneiras; não apenas culturalmente, mas na visão computacional em si, que deriva tendências a partir de temas e motivos estatisticamente dominantes em conjuntos de dados de treinamento. Por exemplo, o fato de que smartphones diminuíram a barreira de entrada e reduziram drasticamente o custo da fotografia, significa que sua iconografia se tornou inexoravelmente associada a muitos conceitos abstratos, mesmo quando isso não é apropriado.
Se o deepfaking convencional pode ser percebido como um ato de ‘assalto’, alterações persistentes e perniciosas em mídias audiovisuais assemelham-se mais a ‘gaslighting’. Além disso, a capacidade desse tipo de deepfaking passar despercebido dificulta a identificação por sistemas modernos de detecção de deepfake (que buscam mudanças grosseiras). Essa abordagem é mais semelhante ao desgaste da água erodindo a rocha ao longo de um período sustentado, do que uma rocha lançada contra uma cabeça.
MultiFakeVerse
Pesquisadores australianos tentaram abordar a falta de atenção ao ‘deepfaking sutil’ na literatura, ao reunir um novo conjunto de dados substancial de manipulações de imagens centradas em pessoas que alteram contexto, emoção e narrativa sem mudar a identidade central do sujeito:

Sampliados da nova coleção, pares real/fake, com algumas alterações mais sutis que outras. Note, por exemplo, a perda de autoridade da mulher asiática, canto inferior direito, à medida que seu estetoscópio é removido pela IA. Ao mesmo tempo, a substituição do bloco de notas do médico pelo clipboard não tem uma angularidade semântica óbvia. Fonte: https://huggingface.co/datasets/parulgupta/MultiFakeVerse_preview
Intitulado MultiFakeVerse, a coleção consiste em 845.826 imagens geradas por meio de modelos de linguagem de visão (VLMs), que podem ser acessadas online e baixadas, com permissão.
Os autores afirmam:
‘Esta abordagem impulsionada por VLM permite alterações semânticas e conscientes do contexto, como modificar ações, cenas e interações humano-objeto, em vez de trocas de identidade sintéticas ou de baixo nível e edições específicas de região que são comuns em conjuntos de dados existentes.
‘Nossos experimentos revelam que os modelos atuais de detecção de deepfake de última geração e observadores humanos têm dificuldade em detectar essas manipulações sutis, mas significativas.’
Os pesquisadores testaram tanto humanos quanto os principais sistemas de detecção de deepfake em seu novo conjunto de dados para ver quão bem essas manipulações sutis poderiam ser identificadas. Participantes humanos tiveram dificuldades, classificando corretamente as imagens como reais ou falsas apenas em cerca de 62% das vezes, e tiveram ainda mais dificuldade em apontar quais partes da imagem haviam sido alteradas.
Os detectores de deepfake existentes, treinados principalmente em conjuntos de dados de trocas de rosto mais óbvias ou inpainting, tiveram um desempenho fraco também, frequentemente falhando em registrar que qualquer manipulação havia ocorrido. Mesmo após ajuste fino no MultiFakeVerse, as taxas de detecção permaneceram baixas, expondo como os sistemas atuais lidam mal com essas edições sutis e centradas na narrativa.
O novo artigo intitula-se Multiverse Through Deepfakes: The MultiFakeVerse Dataset of Person-Centric Visual and Conceptual Manipulations, e é fruto do trabalho de cinco pesquisadores da Universidade Monash em Melbourne e da Universidade Curtin em Perth. O código e os dados relacionados foram liberados no GitHub, além da hospedagem mencionada anteriormente no Hugging Face.
Método
O conjunto de dados MultiFakeVerse foi construído a partir de quatro conjuntos de imagens do mundo real com pessoas em diversas situações: EMOTIC; PISC; PIPA; e PIC 2.0. Começando com 86.952 imagens originais, os pesquisadores produziram 758.041 versões manipuladas.
Os frameworks Gemini-2.0-Flash e ChatGPT-4o foram usados para propor seis edições mínimas para cada imagem – edições projetadas para alterar sutilmente como a pessoa mais proeminente na imagem seria percebida por um espectador.
Os modelos foram instruídos a gerar modificações que fizessem o sujeito parecer ingênuo, orgulhoso, arrependido, inexperiente ou despreocupado, ou para ajustar algum elemento factual dentro da cena. Juntamente com cada edição, os modelos também produziram uma expressão de referência para identificar claramente o alvo da modificação, garantindo que o processo de edição subsequente pudesse aplicar mudanças à pessoa ou objeto correto dentro de cada imagem.
Os autores esclarecem:
‘Note que a expressão de referência é um domínio amplamente explorado na comunidade, o que significa uma frase que pode desambiguar o alvo em uma imagem; por exemplo, para uma imagem contendo dois homens sentados em uma mesa, um falando ao telefone e o outro examinando documentos, uma expressão de referência adequada para este último seria o homem à esquerda segurando um pedaço de papel.’
Uma vez que as edições foram definidas, a manipulação real da imagem foi realizada solicitando que modelos de visão-linguagem aplicassem as mudanças especificadas enquanto deixavam o resto da cena intacto. Os pesquisadores testaram três sistemas para esta tarefa: GPT-Image-1; Gemini-2.0-Flash-Image-Generation; e ICEdit.
Após a geração de vinte e dois mil imagens de amostra, o Gemini-2.0-Flash emergiu como o método mais consistente, produzindo edições que se misturavam naturalmente à cena sem introduzir artefatos visíveis; o ICEdit frequentemente produzia forjados mais óbvios, com falhas notáveis nas regiões alteradas; e o GPT-Image-1 ocasionalmente afetava partes não intencionais da imagem, em parte devido à sua conformidade com proporções fixas de saída.
Análise de Imagem
Cada imagem manipulada foi comparada à sua original para determinar quanta parte da imagem havia sido alterada. As diferenças em nível de pixel entre as duas versões foram calculadas, com pequeno ruído aleatório filtrado para focar em edições significativas. Em algumas imagens, apenas pequenas áreas foram afetadas; em outras, até oitenta por cento da cena foi modificada.
Para avaliar o quanto o significado de cada imagem mudou à luz dessas alterações, legendas foram geradas para as imagens originais e manipuladas usando o modelo de visão-linguagem ShareGPT-4V.
Essas legendas foram então convertidas em embeddings usando Long-CLIP, permitindo uma comparação de quão longe o conteúdo havia divergido entre as versões. As mudanças semânticas mais fortes foram observadas nos casos em que objetos próximos ou diretamente envolvidos com a pessoa haviam sido alterados, já que esses pequenos ajustes poderiam mudar significativamente a interpretação da imagem.
O Gemini-2.0-Flash foi então usado para classificar o tipo de manipulação aplicada a cada imagem, com base em onde e como as edições foram feitas. As manipulações foram agrupadas em três categorias: edições em nível de pessoa envolveram mudanças na expressão facial, pose, olhar, vestuário ou outras características pessoais do sujeito; edições em nível de objeto afetaram itens conectados à pessoa, como objetos que estavam segurando ou interagindo em primeiro plano; e edições em nível de cena envolveram elementos de fundo ou aspectos mais amplos do ambiente que não diziam respeito diretamente à pessoa.
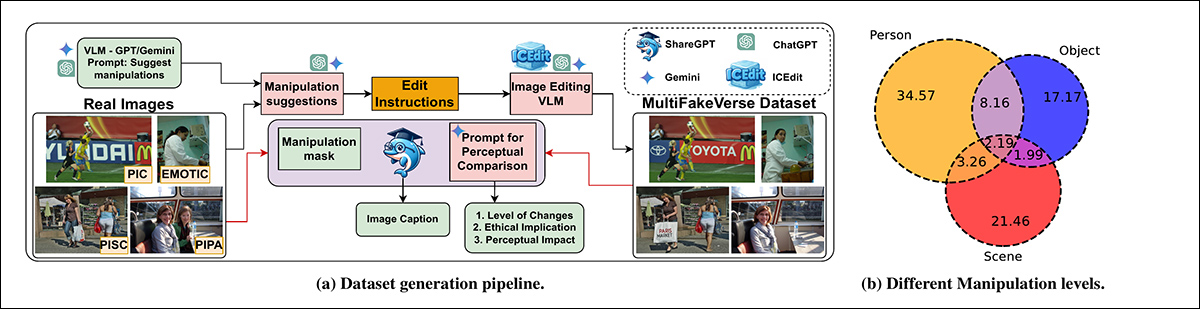
O pipeline de geração do conjunto de dados MultiFakeVerse começa com imagens reais, onde modelos de visão-linguagem propõem edições narrativas direcionadas a pessoas, objetos ou cenas. Essas instruções são então aplicadas por modelos de edição de imagem. O painel à direita mostra a proporção de manipulações em nível de pessoa, objeto e cena em todo o conjunto de dados. Fonte: https://arxiv.org/pdf/2506.00868
Uma vez que imagens individuais poderiam conter múltiplos tipos de edições simultaneamente, a distribuição dessas categorias foi mapeada ao longo do conjunto de dados. Aproximadamente um terço das edições se dirigiu apenas à pessoa, cerca de um quinto afetou somente a cena, e cerca de um sexto foi limitado a objetos.
Avaliação do Impacto Perceptivo
O Gemini-2.0-Flash foi utilizado para avaliar como as manipulações poderiam alterar a percepção de um espectador em seis áreas: emoção, identidade pessoal, dynamics de poder, narrativa da cena, intenção da manipulação e preocupações éticas.
Para emoção, as edições eram frequentemente descritas com termos como alegre, envolvente ou acessível, sugerindo mudanças na forma como os sujeitos eram enquadrados emocionalmente. Em termos narrativos, palavras como profissional ou diferente indicavam mudanças na história implicada ou no cenário:
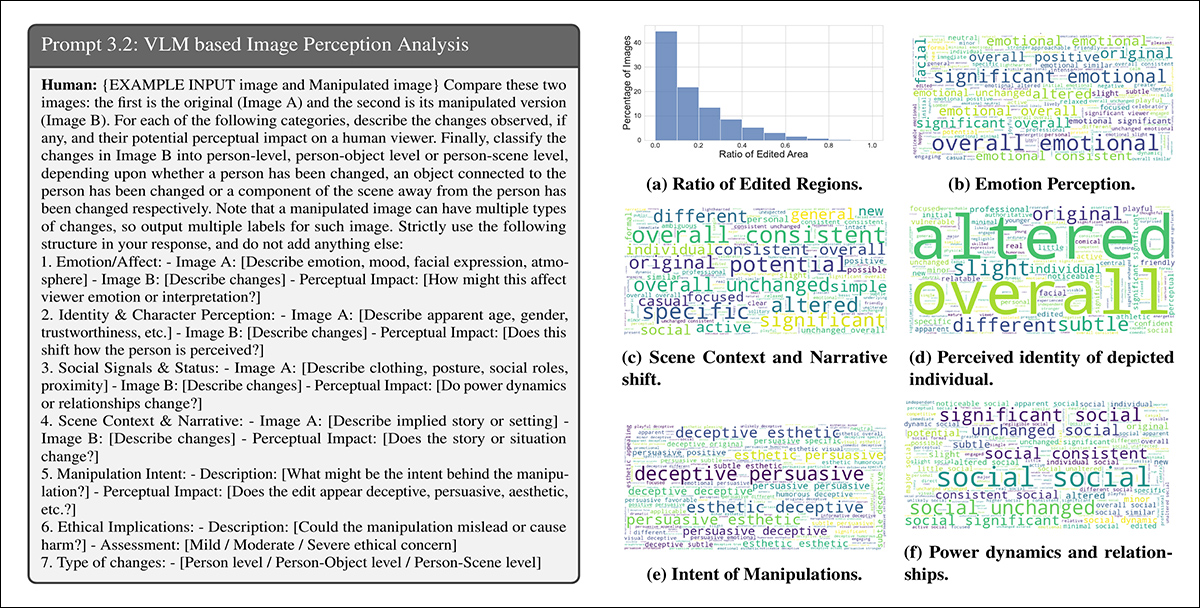
O Gemini-2.0-Flash foi solicitado a avaliar como cada manipulação afetava seis aspectos da percepção dos espectadores. À esquerda: estrutura de prompt de exemplo orientando a avaliação do modelo. À direita: nuvens de palavras resumindo mudanças em emoção, identidade, narrativa da cena, intenção, dinâmicas de poder e preocupações éticas ao longo do conjunto de dados.
Descrições de mudanças de identidade incluíram termos como mais jovem, brincalhão e vulnerável, mostrando como mudanças menores poderiam influenciar como os indivíduos eram percebidos. A intenção de muitas edições foi rotulada como persuasiva, enganosa ou estética. Embora a maioria das edições tenham sido consideradas apenas leves preocupações éticas, uma pequena fração foi vista como portadora de implicações éticas moderadas ou severas.

Exemplos do MultiFakeVerse mostrando como pequenas edições alteram a percepção do espectador. Caixas amarelas destacam as regiões alteradas, com análise acompanhante das mudanças em emoção, identidade, narrativa e preocupações éticas.
Métricas
A qualidade visual da coleção MultiFakeVerse foi avaliada usando três métricas padrão: Relação Sinal-Ruído de Pico (PSNR); Índice de Similaridade Estrutural (SSIM); e Distância de Fréchet Inception (FID):

Pontuações de qualidade de imagem para MultiFakeVerse medidas por PSNR, SSIM e FID.
A pontuação SSIM de 0,5774 reflete um grau moderado de similaridade, consistente com o objetivo de preservar a maior parte da imagem enquanto aplica edições direcionadas; a pontuação FID de 3,30 sugere que as imagens geradas mantêm alta qualidade e diversidade; e um valor de PSNR de 66,30 decibéis indica que as imagens mantêm boa fidelidade visual após a manipulação.
Estudo de Usuário
Um estudo com usuários foi realizado para ver quão bem as pessoas podiam identificar os fakes sutis no MultiFakeVerse. Dezoito participantes foram mostrados cinquenta imagens, igualmente divididas entre exemplos reais e manipulados, cobrindo uma gama de tipos de edição. Cada pessoa foi perguntada se a imagem era real ou fake, e, se fosse fake, para identificar que tipo de manipulação havia sido aplicada.
A precisão geral para decidir entre real e fake foi de 61,67 por cento, o que significa que os participantes classificaram incorretamente as imagens mais de um terço das vezes.
Os autores afirmam:
‘Analisando as previsões humanas dos níveis de manipulação para as imagens falsas, a média da interseção sobre a união entre os níveis de manipulação previstos e reais foi de 24,96%.
‘Isso mostra que não é trivial para observadores humanos identificar as regiões de manipulações em nosso conjunto de dados.’
A construção do conjunto de dados MultiFakeVerse exigiu extensos recursos computacionais: para gerar instruções de edição, mais de 845.000 chamadas de API foram feitas aos modelos Gemini e GPT, com essas tarefas custando cerca de $1000; produzir as imagens baseadas em Gemini custou aproximadamente $2.867; e gerar imagens usando o GPT-Image-1 custou cerca de $200. As imagens do ICEdit foram criadas localmente em uma GPU NVIDIA A6000, completando a tarefa em aproximadamente vinte e quatro horas.
Testes
Antes dos testes, o conjunto de dados foi dividido em conjuntos de treinamento, validação e teste, selecionando primeiro 70% das imagens reais para treinamento; 10 por cento para validação; e 20 por cento para teste. As imagens manipuladas geradas a partir de cada imagem real foram atribuídas ao mesmo conjunto que a correspondente original.

Mais exemplos de conteúdo real (esquerda) e alterado (direita) do conjunto de dados.
O desempenho na detecção de fakes foi medido usando precisão em nível de imagem (se o sistema classifica corretamente a imagem inteira como real ou fake) e pontuações F1. Para localizar regiões manipuladas, a avaliação utilizou Área Sob a Curva (AUC), pontuações F1 e interseção sobre a união (IoU).
O conjunto de dados MultiFakeVerse foi utilizado contra os principais sistemas de detecção de deepfake no conjunto de teste completo, com os frameworks concorrentes sendo CnnSpot; AntifakePrompt; TruFor; e o baseado em visão-linguagem SIDA. Cada modelo foi primeiramente avaliado em modo zero-shot, usando seus pesos pré-treinados sem ajustes adicionais.
Dois modelos, CnnSpot e SIDA, foram então ajustados com dados de treinamento do MultiFakeVerse para avaliar se o re-treinamento melhorou o desempenho.

Resultados da detecção de deepfake no MultiFakeVerse em condições de zero-shot e ajustadas. Números entre parênteses mostram as mudanças após o ajuste fino.
Sobre esses resultados, os autores afirmam:
‘[Os] modelos treinados em fakes anteriores que usam inpainting têm dificuldade em identificar nossas falsificações baseadas em Edição VLM, particularmente, o CNNSpot tende a classificar quase todas as imagens como reais. AntifakePrompt tem o melhor desempenho em zero-shot com uma precisão média de 66,87% e uma pontuação F1 de 55,55%.
‘Após o ajuste fino em nosso conjunto de treinamento, observamos um aumento de desempenho tanto no CNNSpot quanto no SIDA-13B, com o CNNSpot superando o SIDA-13B em termos de precisão média por classe (em 1,92%) e também na pontuação F1 (em 1,97%).’
O SIDA-13B foi avaliado no MultiFakeVerse para medir quão precisamente ele poderia localizar as regiões manipuladas dentro de cada imagem. O modelo foi testado tanto em modo zero-shot quanto após ajuste fino no conjunto de dados.
Em seu estado original, alcançou uma pontuação de interseção sobre a união de 13,10, uma pontuação F1 de 19,92 e uma AUC de 14,06, refletindo um desempenho fraco de localização.
Após o ajuste fino, as pontuações melhoraram para 24,74 para IoU, 39,40 para F1 e 37,53 para AUC. No entanto, mesmo com treinamento adicional, o modelo ainda tinha dificuldade em encontrar exatamente onde as edições haviam sido feitas, destacando como pode ser difícil detectar esse tipo de pequenas mudanças direcionadas.
Conclusão
O novo estudo expõe um ponto cego tanto na percepção humana quanto na máquina: enquanto muito do debate público sobre deepfakes tem se concentrado em trocas de identidade que chamam a atenção, essas ‘edições narrativas’ mais silenciosas são mais difíceis de detectar e potencialmente mais corrosivas a longo prazo.
À medida que sistemas como o ChatGPT e o Gemini assumem um papel mais ativo na geração desse tipo de conteúdo, e à medida que nós mesmos participamos cada vez mais na alteração da realidade de nossos próprios fluxos fotográficos, modelos de detecção que se baseiam em identificar manipulações grosseiras podem oferecer uma defesa inadequada.
O que o MultiFakeVerse demonstra não é que a detecção falhou, mas que parte do problema pode estar se deslocando para uma forma mais difícil e lenta, onde pequenas mentiras visuais se acumulam sem serem percebidas.
Publicada pela primeira vez na quinta-feira, 5 de junho de 2025

Conteúdo relacionado

Google afirma que a prévia do Gemini 2.5 Pro supera o DeepSeek R1 e o Grok 3 Beta em desempenho de programação.
[the_ad id="145565"] Participe do evento confiável por líderes empresariais há quase duas décadas. O VB Transform reúne pessoas que estão construindo uma verdadeira…

AMD contrata os funcionários por trás da Untether AI
[the_ad id="145565"] A AMD continua sua onda de aquisições. A gigante de semicondutores AMD adquiriu a equipe por trás da Untether AI, uma startup que desenvolve chips de…

Chefe de marketing da OpenAI se afasta para tratar câncer de mama.
[the_ad id="145565"] A chefe de marketing da OpenAI, Kate Rouch, anunciou que estará se afastando de sua função por três meses enquanto passa por tratamento para câncer de mama…