


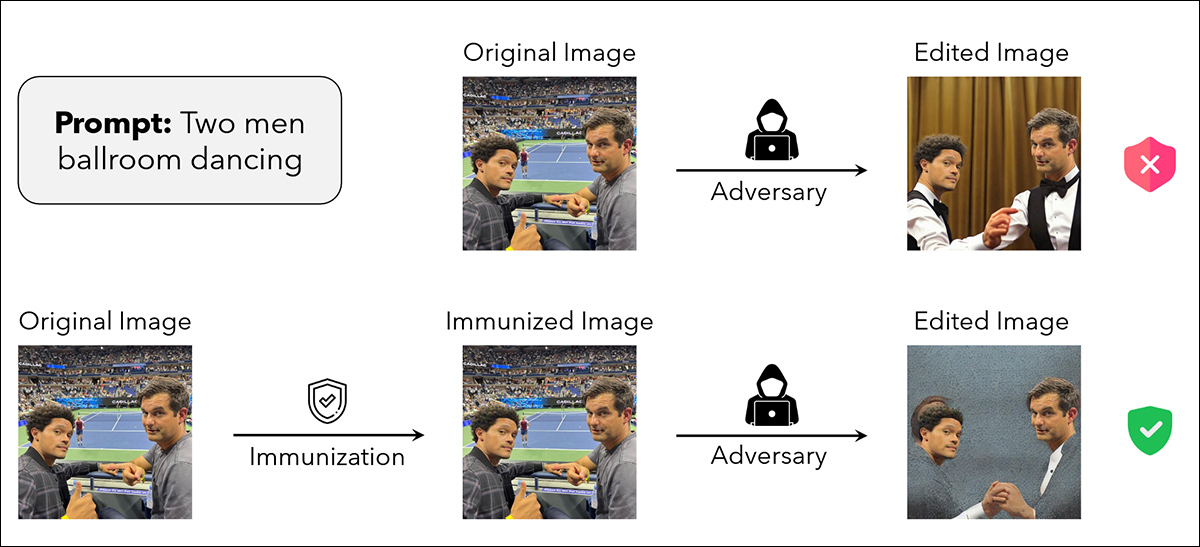
Novas pesquisas sugerem que ferramentas de marcação destinadas a bloquear edições de imagens por IA podem ter o efeito oposto. Em vez de impedir que modelos como o Stable Diffusion façam alterações, algumas proteções realmente ajudam a IA a seguir as instruções de edição mais de perto, tornando manipulações indesejadas ainda mais fáceis.
Existem correntes notáveis e robustas na literatura de visão computacional dedicadas a proteger imagens com direitos autorais de serem treinadas em modelos de IA ou utilizadas em processos diretos de imagem para imagem. Sistemas deste tipo são geralmente destinados a Modelos de Difusão Latente (LDMs) como o Stable Diffusion e o Flux, que utilizam procedimentos baseados em ruído para codificar e decodificar imagens.
Ao inserir ruído adversarial em imagens que parecem normais, é possível fazer com que detectores de imagem adivinhem incorretamente o conteúdo da imagem e impedir que sistemas geradores explorem dados protegidos:
Do artigo do MIT ‘Raising the Cost of Malicious AI-Powered Image Editing’, exemplos de uma imagem fonte ‘imunizada’ contra manipulação (linha inferior). Fonte: https://arxiv.org/pdf/2302.06588
Desde um retrocesso dos artistas contra o uso liberal de imagens extraídas da web (incluindo imagens com direitos autorais) pelo Stable Diffusion em 2023, a cena de pesquisa produziu várias variações sobre o mesmo tema – a ideia de que as imagens podem ser ‘envenenadas’ de forma invisível contra serem treinadas em sistemas de IA ou sugadas para pipelines de IA generativa, sem afetar adversamente a qualidade da imagem, para o espectador médio.
Em todos os casos, há uma correlação direta entre a intensidade da perturbação imposta, a extensão pela qual a imagem é posteriormente protegida e a extensão pela qual a imagem não parece tão boa quanto deveria:

Embora a qualidade do PDF de pesquisa não ilustre completamente o problema, quantidades maiores de perturbação adversarial sacrificam qualidade por segurança. Aqui vemos a gama de distúrbios de qualidade no projeto ‘Fawkes’ de 2020 liderado pela Universidade de Chicago. Fonte: https://arxiv.org/pdf/2002.08327
De particular interesse para artistas que buscam proteger seus estilos contra apropriações não autorizadas está a capacidade de tais sistemas não apenas de obfuscar identidade e outras informações, mas de ‘convencer’ um processo de treinamento de IA de que está vendo algo diferente do que realmente está vendo, para que conexões não se formem entre domínios semânticos e visuais para dados ‘protegidos’ (ou seja, um prompt como ‘No estilo de Paul Klee’).

Mist e Glaze são dois métodos de injeção populares capazes de prevenir, ou pelo menos dificultar severamente, tentativas de usar estilos com direitos autorais em fluxos de trabalho e rotinas de treinamento de IA. Fonte: https://arxiv.org/pdf/2506.04394
Gol Contra
Agora, novas pesquisas dos EUA descobriram que não apenas as perturbações podem falhar em proteger uma imagem, mas que adicionar perturbação pode, na verdade, melhorar a explotabilidade da imagem em todos os processos de IA contra os quais a perturbação deveria imunizá-la.
O artigo afirma:
‘Em nossos experimentos com vários métodos de proteção de imagem baseados em perturbação em múltiplos domínios (imagens de cena natural e obras de arte) e tarefas de edição (geração de imagem para imagem e edição de estilo), descobrimos que tal proteção não alcança esse objetivo totalmente.
‘Em muitos cenários, a edição baseada em difusão de imagens protegidas gera uma imagem de saída desejável que adere precisamente ao prompt de orientação.
‘Nossas descobertas sugerem que adicionar ruído às imagens pode paradoxalmente aumentar sua associação com os prompts de texto dados durante o processo de geração, levando a consequências indesejadas como melhores edições resultantes.
‘Portanto, argumentamos que métodos baseados em perturbação podem não fornecer uma solução suficiente para uma proteção robusta de imagens contra edições baseadas em difusão.’
Nos testes, as imagens protegidas foram expostas a dois cenários familiares de edição de IA: geração simples de imagem para imagem e transferência de estilo. Esses processos refletem as maneiras comuns de que os modelos de IA poderiam explorar conteúdo protegido, seja alterando diretamente uma imagem ou tomando emprestados seus traços estilísticos para uso em outros lugares.
As imagens protegidas, extraídas de fontes padrão de fotografia e arte, foram executadas por essas pipelines para ver se as perturbações adicionadas poderiam bloquear ou degradar as edições.
Em vez disso, a presença de proteção muitas vezes parecia aprimorar o alinhamento do modelo com os prompts, produzindo saídas limpas e precisas onde algum fracasso era esperado.
Os autores aconselham, de certa forma, que esse método muito popular de proteção pode estar proporcionando uma falsa sensação de segurança, e que quaisquer abordagens de imunização baseadas em perturbação devem ser testadas minuciosamente contra os próprios métodos dos autores.
Método
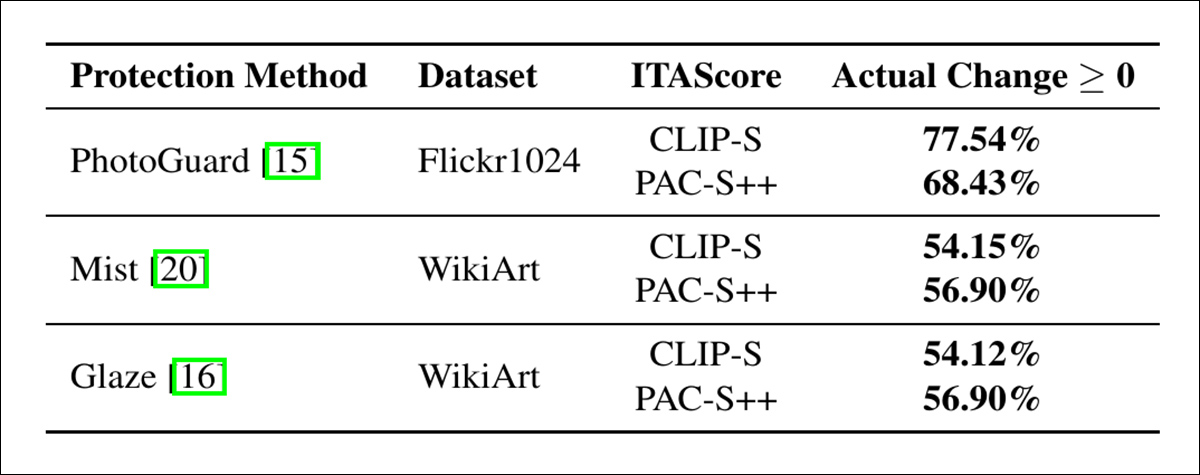
Os autores realizaram experimentos utilizando três métodos de proteção que aplicam perturbações adversariais cuidadosamente projetadas: PhotoGuard; Mist; e Glaze.

Glaze, um dos frameworks testados pelos autores, ilustrando exemplos de proteção Glaze para três artistas. As duas primeiras colunas mostram as obras originais; a terceira coluna mostra os resultados de imitação sem proteção; a quarta, versões transferidas de estilo usadas para otimização de camuflagem, juntamente com o nome do estilo alvo. As quintas e sextas colunas mostram os resultados de imitação com camuflagem aplicada em níveis de p = 0.05 e p = 0.1. Todos os resultados usam modelos de Stable Diffusion. https://arxiv.org/pdf/2302.04222
PhotoGuard foi aplicado a imagens de cena natural, enquanto Mist e Glaze foram usados em obras de arte (ou seja, domínios ‘artistically-styled’).
Os testes cobriram imagens naturais e artísticas para refletir usos possíveis no mundo real. A eficácia de cada método foi avaliada verificando se um modelo de IA ainda poderia produzir edições realistas e relevantes ao prompt ao trabalhar em imagens protegidas; se as imagens resultantes parecerem convincentes e corresponderem aos prompts, a proteção foi considerada como falhada.
O Stable Diffusion v1.5 foi usado como o gerador de imagens pré-treinado para as tarefas de edição dos pesquisadores. Foram selecionadas cinco sementes para garantir a reprodutibilidade: 9222, 999, 123, 66 e 42. Todas as outras configurações de geração, como escala de orientação, força e número total de etapas, seguiram os valores padrão usados nos experimentos do PhotoGuard.
O PhotoGuard foi testado em imagens de cena natural usando o conjunto de dados Flickr8k, que contém mais de 8.000 imagens emparelhadas com até cinco legendas cada.
Pontos Opostos
Dois conjuntos de legendas modificadas foram criados a partir da primeira legenda de cada imagem com a ajuda do Claude Sonnet 3.5. Um conjunto continha prompts que eram contextualmente próximos às legendas originais; o outro conjunto continha prompts que eram contextualmente distantes.
Por exemplo, a partir da legenda original ‘Uma jovem garota em um vestido rosa entrando em uma cabana de madeira’, um prompt próximo seria ‘Um jovem garoto em uma camisa azul indo para uma casa de tijolos’. Por outro lado, um prompt distante seria ‘Dois gatos relaxando em um sofá’.
Prompts próximos foram construídos substituindo substantivos e adjetivos por termos semanticamente semelhantes; prompts distantes foram gerados instruindo o modelo a criar legendas que eram contextualmente muito diferentes.
Todas as legendas geradas foram verificadas manualmente para qualidade e relevância semântica. O Universal Sentence Encoder do Google foi utilizado para calcular pontuações de similaridade semântica entre as legendas originais e modificadas:
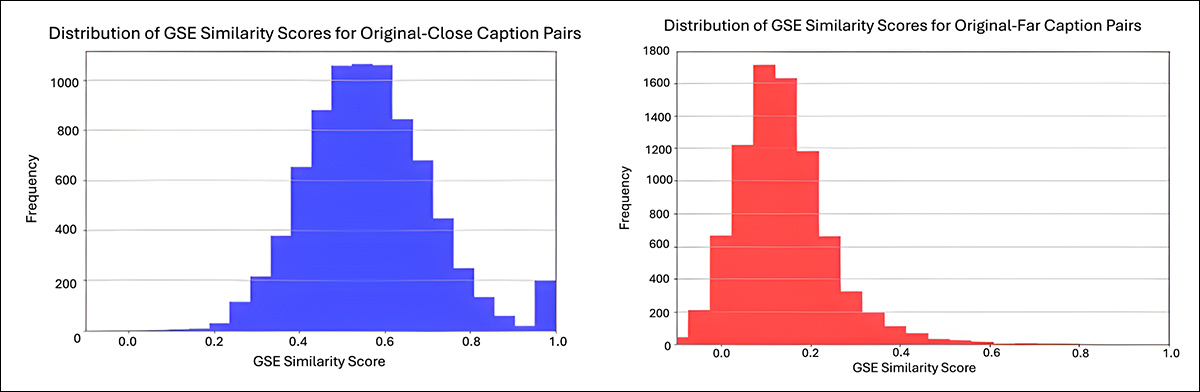
Dos materiais suplementares, distribuições de similaridade semântica para as legendas modificadas usadas nos testes Flickr8k. O gráfico à esquerda mostra as pontuações de similaridade para legendas modificadas de forma próxima, com média em torno de 0.6. O gráfico à direita mostra as legendas modificadas extensivamente, com média em torno de 0.1, refletindo maior distância semântica das legendas originais. Os valores foram calculados usando o Universal Sentence Encoder do Google. Fonte: https://sigport.org/sites/default/files/docs/IncompleteProtection_SM_0.pdf
Cada imagem, junto com sua versão protegida, foi editada usando tanto os prompts próximos quanto os distantes. O Avaliador de Qualidade de Imagem Sem Referência/Distante (BRISQUE) foi utilizado para avaliar a qualidade da imagem:

Resultados de geração de imagem para imagem em fotografias naturais protegidas pelo PhotoGuard. Apesar da presença de perturbações, o Stable Diffusion v1.5 seguiu com sucesso tanto mudanças semânticas pequenas quanto grandes nos prompts de edição, produzindo saídas realistas que correspondem às novas instruções.
As imagens geradas marcaram 17.88 no BRISQUE, com 17.82 para prompts próximos e 17.94 para prompts distantes, enquanto as imagens originais marcaram 22.27. Isso mostra que as imagens editadas permaneceram próximas em qualidade das originais.
Métricas
Para avaliar como as proteções interferiam na edição de IA, os pesquisadores mediram o quão de perto as imagens finais correspondiam às instruções que receberam, usando sistemas de pontuação que comparavam o conteúdo da imagem ao prompt de texto, para ver quão bem eles se alinham.
Para isso, a métrica CLIP-S utiliza um modelo que pode entender tanto imagens quanto texto para verificar quão semelhantes eles são, enquanto a PAC-S++ adiciona amostras extras criadas por IA para alinhar sua comparação mais de perto com uma estimativa humana.
Essas pontuações de Alinhamento Imagem-Texto (ITA) indicam quão precisamente a IA seguiu as instruções ao modificar uma imagem protegida: se uma imagem protegida ainda resultou em uma saída altamente alinhada, isso significa que a proteção foi considerada como falhada ao bloquear a edição.
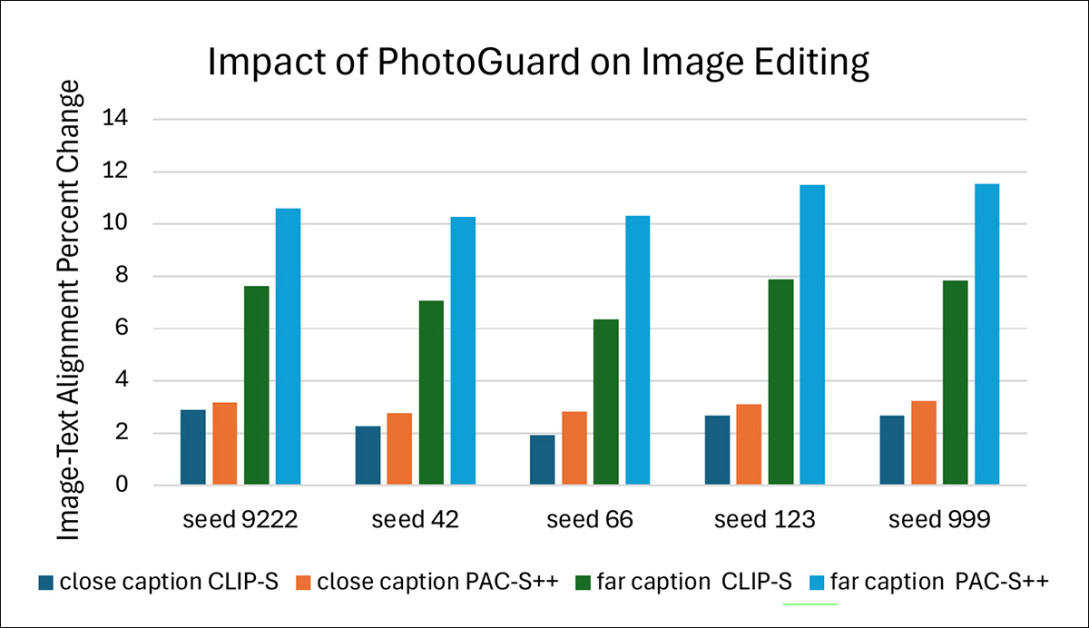
Efeito da proteção no conjunto de dados Flickr8k em cinco sementes, usando tanto prompts próximos quanto distantes. O alinhamento imagem-texto foi medido usando pontuações CLIP-S e PAC-S++.
Os pesquisadores compararam quão bem a IA seguiu os prompts ao editar imagens protegidas em relação às não protegidas. Eles primeiro analisaram a diferença entre as duas, chamada de Mudança Real. Em seguida, a diferença foi dimensionada para criar uma Mudança Percentual, facilitando a comparação de resultados em muitos testes.
Esse processo revelou se as proteções tornaram mais difícil ou mais fácil para a IA corresponder aos prompts. Os testes foram repetidos cinco vezes usando diferentes sementes aleatórias, cobrindo tanto mudanças pequenas quanto grandes nas legendas originais.
Ataque Artístico
Para os testes em fotografias naturais, foi utilizado o conjunto de dados Flickr1024, que contém mais de mil imagens de alta qualidade. Cada imagem foi editada com prompts que seguiam o padrão: ‘mudar o estilo para [V]’, onde [V] representava um dos sete estilos artísticos famosos: Cubismo; Pós-Impressionismo; Impressionismo; Surrealismo; Barroco; Fauvismo; e Renascimento.
O processo envolveu aplicar o PhotoGuard às imagens originais, gerando versões protegidas, e então executando tanto as imagens protegidas quanto as não protegidas através do mesmo conjunto de edições de transferência de estilo:

Versões originais e protegidas de uma imagem de cena natural, cada uma editada para aplicar estilos Cubismo, Surrealismo e Fauvismo.
Para testar os métodos de proteção em obras de arte, a transferência de estilo foi realizada em imagens do conjunto de dados WikiArt, que reúne uma ampla gama de estilos artísticos. Os prompts de edição seguiram o mesmo formato de antes, instruindo a IA a mudar o estilo para um estilo selecionado aleatoriamente e não relacionado extraído dos rótulos do WikiArt.
Ambos os métodos de proteção Glaze e Mist foram aplicados às imagens antes das edições, permitindo que os pesquisadores observassem quão bem cada defesa poderia bloquear ou distorcer os resultados da transferência de estilo:

Exemplos de como os métodos de proteção afetam a transferência de estilo em obras de arte. A imagem original Barroca é mostrada ao lado de versões protegidas por Mist e Glaze. Após a aplicação da transferência de estilo Cubismo, as diferenças em como cada proteção altera a saída final podem ser vistas.
Os pesquisadores testaram as comparações quantitativamente também:
Mudanças nas pontuações de alinhamento imagem-texto após edições de transferência de estilo.
Dos resultados, os autores comentam:
‘Os resultados destacam uma limitação significativa das perturbações adversariais para proteção. Em vez de impedir o alinhamento, perturbações adversariais frequentemente aumentam a responsividade do modelo gerador a prompts, inadvertidamente permitindo que exploradores produzam saídas que se alinham mais de perto a seus objetivos. Tal proteção não é disruptiva ao processo de edição de imagem e pode não ser capaz de impedir que agentes maliciosos copiem material não autorizado.
‘As consequências não intencionais do uso de perturbações adversariais revelam vulnerabilidades nos métodos existentes e destacam a necessidade urgente de técnicas de proteção mais eficazes.’
Os autores explicam que os resultados inesperados podem ser atribuídos ao funcionamento dos modelos de difusão: os LDMs editam imagens convertendo-as primeiro em uma versão comprimida chamada latente; o ruído é adicionado a essa latente através de muitos passos, até que os dados se tornem quase aleatórios.
O modelo reverte esse processo durante a geração, removendo o ruído etapa por etapa. Em cada estágio dessa reversão, o prompt de texto ajuda a guiar como o ruído deve ser limpo, moldando gradualmente a imagem para corresponder ao prompt:

Comparação entre gerações de uma imagem não protegida e uma imagem protegida pelo PhotoGuard, com estados latentes intermediários convertidos de volta em imagens para visualização.
Os métodos de proteção adicionam pequenas quantidades de ruído extra à imagem original antes de entrar nesse processo. Enquanto essas perturbações são menores no início, elas se acumulam à medida que o modelo aplica suas próprias camadas de ruído.
Esse acúmulo deixa mais partes da imagem ‘incertas’ quando o modelo começa a remover o ruído. Com maior incerteza, o modelo se apoia mais fortemente no prompt de texto para preencher os detalhes ausentes, dando ao prompt ainda mais influência do que normalmente teria.
Na prática, as proteções tornam mais fácil para a IA remodelar a imagem para corresponder ao prompt, em vez de mais difícil.
Finalmente, os autores realizaram um teste que substituiu as perturbações criadas pelo artigo Raising the Cost of Malicious AI-Powered Image Editing paper por ruído gaussiano puro.
Os resultados seguiram o mesmo padrão observado anteriormente: em todos os testes, os valores de Mudança Percentual permaneceram positivos. Mesmo esse ruído aleatório e não estruturado levou a um alinhamento mais forte entre as imagens geradas e os prompts.

Efeito de proteção simulada utilizando ruído gaussiano no conjunto de dados Flickr8k.
Isso apoiou a explicação subjacente de que qualquer ruído adicional, independentemente de seu design, cria maior incerteza para o modelo durante a geração, permitindo que o prompt de texto exerça ainda mais controle sobre a imagem final.
Conclusão
A cena de pesquisa tem insistido nas perturbações adversariais sobre a questão dos direitos autorais dos LDMs quase desde que os LDMs existem; mas nenhuma solução resiliente surgiu da enorme quantidade de artigos publicados nesse sentido.
Ou as perturbações impostas reduzem excessivamente a qualidade da imagem, ou os padrões se provam não resilientes a manipulações e processos transformativos.
No entanto, é um sonho difícil de abandonar, já que a alternativa parece ser um monitoramento de terceiros e frameworks de proveniência, como o esquema C2PA liderado pela Adobe, que busca manter uma cadeia de custódia para imagens desde o sensor da câmera, mas que não tem uma conexão inata com o conteúdo retratado.
Em qualquer caso, se a perturbação adversarial está realmente piorando o problema, como o novo artigo indica que poderia ser verdade em muitos casos, fica-se perguntando se a busca por proteção de direitos autorais por meio de tais meios se enquadra na categoria de ‘alquimia’.
Publicada pela primeira vez na segunda-feira, 9 de junho de 2025

Conteúdo relacionado

A computação baseada em agentes está superando a web que conhecemos.
[the_ad id="145565"] Participe do evento confiável por líderes de empresas há quase duas décadas. O VB Transform reúne as pessoas que estão construindo uma verdadeira…

Por que a maior aposta da Meta em IA não está em modelos—mas sim em dados
[the_ad id="145565"] O suposto investimento de $10 bilhões da Meta na Scale AI vai muito além de uma simples rodada de financiamento—ele sinaliza uma evolução estratégica…

Sam Altman pede por ‘privilégio da IA’ enquanto a OpenAI esclarece ordem judicial sobre retenção de sessões temporárias e deletadas do ChatGPT.
[the_ad id="145565"] Sure, here's the rewritten content in Portuguese while keeping the HTML tags intact: <div> <div id="boilerplate_2682874"…