


Participe do evento confiável por líderes empresariais há quase duas décadas. O VB Transform reúne pessoas que estão construindo uma verdadeira estratégia de IA empresarial. Saiba mais
Nota do editor: Louis irá conduzir uma mesa-redonda editorial sobre este tema no VB Transform neste mês. Registre-se hoje.
Modelos de IA estão sob ataque. Com 77% das empresas já afetadas por ataques adversariais a modelos e 41% desses ataques explorando injeções de prompt e envenenamento de dados, a técnica dos atacantes está superando as defesas cibernéticas existentes.
Para reverter essa tendência, é crucial repensar como a segurança é integrada nos modelos sendo desenvolvidos today. As equipes de DevOps precisam mudar de uma defesa reativa para testes adversariais contínuos em cada etapa.
A Red Teaming precisa ser o cerne
Proteger os modelos de linguagem de grande porte (LLMs) durante os ciclos de DevOps requer a red teaming como um componente central do processo de criação do modelo. Em vez de tratar a segurança como um obstáculo final, que é típico em pipelines de aplicativos web, os testes adversariais contínuos precisam ser integrados em cada fase do Ciclo de Vida do Desenvolvimento de Software (SDLC).
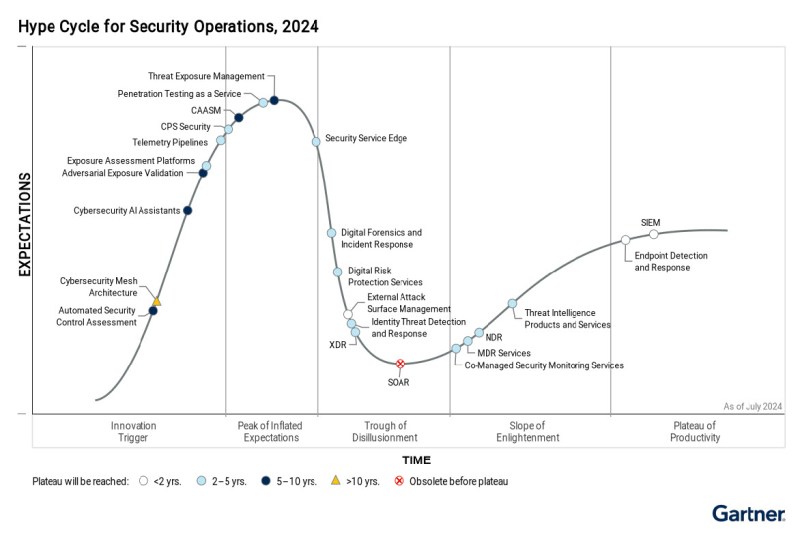
Adotar uma abordagem mais integrativa aos fundamentos do DevSecOps está se tornando necessário para mitigar os crescentes riscos de injeções de prompt, envenenamento de dados e a exposição de dados sensíveis. Ataques severos como esses estão se tornando mais prevalentes, ocorrendo desde o design do modelo até a implantação, tornando o monitoramento contínuo essencial.
A orientação recente da Microsoft sobre planejamento red teaming para modelos de linguagem de grande porte (LLMs) e suas aplicações fornece uma metodologia valiosa para iniciar um processo integrado. O Framework de Gestão de Risco de IA do NIST reforça isso, enfatizando a necessidade de uma abordagem mais proativa e contínua a testes adversariais e mitigação de riscos. A recente red teaming da Microsoft de mais de 100 produtos de IA generativa sublinha a necessidade de integrar a detecção automatizada de ameaças com supervisão especializada em todo o desenvolvimento do modelo.
À medida que os frameworks regulatórios, como o Ato de IA da UE, exigem testes adversariais rigorosos, a integração da red teaming contínua garante a conformidade e a segurança aprimorada.
A abordagem da OpenAI para red teaming integra a red teaming externa desde a fase de design até a implantação, confirmando que testes de segurança consistentes e proativos são cruciais para o sucesso do desenvolvimento de LLM.
Por que as defesas cibernéticas tradicionais falham contra a IA
As abordagens tradicionais de cibersegurança falham contra ameaças impulsionadas por IA porque são fundamentalmente diferentes dos ataques convencionais. À medida que as técnicas dos adversários superam as abordagens tradicionais, novas técnicas para red teaming são necessárias. Aqui está um exemplo de diversos tipos de técnicas especificamente criadas para atacar modelos de IA durante os ciclos de DevOps e uma vez em operação:
- Envenenamento de dados: Os adversários injetam dados corrompidos em conjuntos de treinamento, fazendo com que os modelos aprendam incorretamente e criando imprecisões persistentes e erros operacionais até que sejam descobertos. Isso muitas vezes mina a confiança nas decisões baseadas em IA.
- Evitação do modelo: Os adversários introduzem mudanças sutis e cuidadosamente elaboradas na entrada, permitindo que dados maliciosos escapem dos sistemas de detecção ao explorar as limitações inerentes das regras estáticas e controles de segurança baseados em padrões.
- Inversão do modelo: Consultas sistemáticas contra modelos de IA permitem que adversários extraiam informações confidenciais, potencialmente expondo dados de treinamento sensíveis ou proprietários e criando riscos permanentes de privacidade.
- Injeção de prompt: Os adversários elaboram entradas especificamente projetadas para enganar a IA generativa em contornar salvaguardas, produzindo resultados nocivos ou não autorizados.
- Riscos da Fronteira de Uso Duplo: No recente artigo, Benchmark Early and Red Team Often: A Framework for Assessing and Managing Dual-Use Hazards of AI Foundation Models, pesquisadores do Centro de Cibersegurança de Longo Prazo da Universidade da Califórnia, Berkeley enfatizam que modelos de IA avançados diminuem significativamente as barreiras, permitindo que não especialistas realizem ciberataques sofisticados, ameaças químicas ou outros exploits complexos, moldando fundamentalmente o panorama global de ameaças e intensificando a exposição ao risco.
As Operações de Aprendizado de Máquina Integradas (MLOps) ainda agravam esses riscos, ameaças e vulnerabilidades. A natureza interconectada dos pipelines de desenvolvimento de LLM e de IA mais ampla amplifica essas superfícies de ataque, exigindo melhorias na red teaming.
Líderes de cibersegurança estão adotando cada vez mais testes adversariais contínuos para combater essas ameaças emergentes à IA. Exercícios estruturados de red team são agora essenciais, simulando realisticamente ataques focados em IA para descobrir vulnerabilidades ocultas e fechar lacunas de segurança antes que os atacantes possam explorá-las.
Como líderes de IA se mantêm à frente dos atacantes com red teaming
Adversários continuam a acelerar o uso de IA para criar novas formas de técnica que desafiam as defesas cibernéticas tradicionais existentes. Seu objetivo é explorar o maior número possível de vulnerabilidades emergentes.
Líderes da indústria, incluindo as principais empresas de IA, responderam incorporando estratégias de red teaming sistemáticas e sofisticadas no cerne de sua segurança de IA. Em vez de tratar a red teaming como uma verificação ocasional, eles realizam testes adversariais contínuos, combinando insights humanos especializados, automação disciplinada e avaliações iterativas de humanos no processo para descobrir e reduzir ameaças antes que os atacantes possam explorá-las de forma proativa.
Suas metodologias rigorosas permitem que identifiquem fraquezas e endureçam sistematicamente seus modelos contra cenários adversariais do mundo real em evolução.
Especificamente:
- A Anthropic depende de insights rigorosos de humanos como parte de sua metodologia contínua de red teaming. Ao integrar totalmente as avaliações humanas com ataques adversariais automatizados, a empresa identifica proativamente vulnerabilidades e continuamente refina a confiabilidade, precisão e interpretabilidade de seus modelos.
- A Meta escala a segurança do modelo de IA por meio de testes adversariais centrados na automação. Seu Multi-round Automatic Red-Teaming (MART) gera sistematicamente prompts adversariais iterativos, descobrindo rapidamente vulnerabilidades ocultas e restringindo eficientemente os vetores de ataque em implantações extensas de IA.
- A Microsoft aproveita a colaboração interdisciplinar como a base de sua força em red teaming. Usando sua Ferramenta de Identificação de Risco em Python (PyRIT), a Microsoft une a experiência em cibersegurança e análises avançadas com validação disciplinada por seres humanos, acelerando a detecção de vulnerabilidades e fornecendo informações detalhadas e acionáveis para fortalecer a resiliência do modelo.
- A OpenAI aproveita a expertise em segurança global para fortalecer as defesas de IA em escala. Combinando insights de especialistas em segurança externa com avaliações adversariais automatizadas e rigorosos ciclos de validação humana, a OpenAI aborda proativamente ameaças sofisticadas, visando especificamente desinformação e vulnerabilidades de injeção de prompt para manter um desempenho robusto do modelo.
Em resumo, os líderes de IA sabem que se manter à frente dos atacantes exige vigilância contínua e proativa. Ao incorporar supervisão humana estruturada, automação disciplinada e refinamento iterativo em suas estratégias de red teaming, esses líderes da indústria estabelecem o padrão e definem o manual para uma IA resiliente e confiável em escala.
À medida que os ataques a LLMs e modelos de IA continuam a evoluir rapidamente, as equipes de DevOps e DevSecOps devem coordenar seus esforços para enfrentar o desafio de melhorar a segurança da IA. A VentureBeat está identificando as seguintes cinco estratégias de alto impacto que os líderes de segurança podem implementar imediatamente:
- Integrar a segurança desde o início (Anthropic, OpenAI)
Construa testes adversariais diretamente no design inicial do modelo e throughout toda a sua vida. Detectar vulnerabilidades precocemente reduz riscos, interrupções e custos futuros.
- Implantar monitoramento adaptativo em tempo real (Microsoft)
Defesas estáticas não podem proteger sistemas de IA contra ameaças avançadas. Utilize ferramentas contínuas impulsionadas por IA como o CyberAlly para detectar e responder rapidamente a anomalias sutis, minimizando a janela de exploração.
- Equilibrar automação com julgamento humano (Meta, Microsoft)
Automação pura perde nuances; testes manuais sozinhos não escalam. Combine testes adversariais automatizados e varreduras de vulnerabilidades com análise humana especializada para garantir insights precisos e acionáveis.
- Engajar regularmente equipes externas de red team (OpenAI)
As equipes internas desenvolvem pontos cegos. Avaliações externas periódicas revelam vulnerabilidades ocultas, validam independentemente suas defesas e impulsionam a melhoria contínua.
- Manter inteligência de ameaças dinâmica (Meta, Microsoft, OpenAI)
Atacantes evoluem constantemente as táticas. Integre continuamente inteligência de ameaças em tempo real, análise automatizada e insights especializados para atualizar e fortalecer sua postura defensiva proativamente.
Juntas, essas estratégias garantem que os fluxos de trabalho de DevOps permaneçam resilientes e seguros, enquanto se mantêm à frente das ameaças adversariais em evolução.
A red teaming não é mais opcional; é essencial
As ameaças de IA tornaram-se muito sofisticadas e frequentes para se confiar apenas em abordagens tradicionais e reativas de cibersegurança. Para se manter à frente, as organizações devem incorporar continuamente e de forma proativa testes adversariais em cada estágio do desenvolvimento do modelo. Ao equilibrar automação com expertise humana e adaptar dinamicamente suas defesas, os principais fornecedores de IA provam que uma segurança robusta e a inovação podem coexistir.
Em última análise, a red teaming não se trata apenas de defender modelos de IA. Trata-se de garantir confiança, resiliência e confiança em um futuro cada vez mais moldado por IA.
Junte-se a mim no Transform 2025
Estarei hospedando duas mesas-redondas focadas em cibersegurança no Transform 2025 da VentureBeat, que será realizado de 24 a 25 de junho em Fort Mason, San Francisco. Registre-se para participar da conversa.
Minha sessão incluirá uma sobre red teaming, Red Teaming de IA e Testes Adversariais, mergulhando em estratégias para testar e fortalecer soluções de cibersegurança impulsionadas por IA contra ameaças adversariais sofisticadas.


Conteúdo relacionado

DeepCoder-14B: O Modelo de IA Open Source que Aumenta a Produtividade e Inovação dos Desenvolvedores
[the_ad id="145565"] A Inteligência Artificial (IA) está mudando a forma como o software é desenvolvido. Geradores de código impulsionados por IA tornaram-se ferramentas…

Os modelos de raciocínio realmente pensam ou não? Pesquisa da Apple gera um debate acalorado.
[the_ad id="145565"] Participe do evento confiável pelos líderes empresariais há quase duas décadas. O VB Transform reúne pessoas que constroem uma verdadeira estratégia de IA…

Além da arquitetura GPT: Por que a abordagem de Difusão do Google pode redefinir a implementação de LLMs
[the_ad id="145565"] Participe do evento confiável por líderes empresariais há quase duas décadas. O VB Transform reúne pessoas que estão construindo uma verdadeira estratégia…