


Participe do evento confiável pelos líderes empresariais há quase duas décadas. O VB Transform reúne pessoas que constroem uma verdadeira estratégia de IA empresarial. Saiba mais
O grupo de aprendizado de máquina da Apple levantou uma tempestade retórica no início deste mês com a publicação de “A Ilusão do Pensar”, um artigo de pesquisa de 53 páginas que argumenta que os chamados modelos amplos de raciocínio (LRMs) ou modelos de linguagem de raciocínio (LLMs de raciocínio), como a série “o” da OpenAI e o Google Gemini-2.5 Pro, não realmente se engajam em “pensar” ou “raciocinar” de forma independente a partir dos princípios gerais aprendidos de seus dados de treinamento.
Em vez disso, os autores sustentam que esses LLMs de raciocínio estão realizando uma espécie de “combinação de padrões” e que sua aparente capacidade de raciocínio parece desmoronar quando uma tarefa se torna muito complexa, sugerindo que sua arquitetura e desempenho não são um caminho viável para melhorar a IA generativa até o ponto de se tornar inteligência geral artificial (AGI), que a OpenAI define como um modelo que supera humanos na maioria dos trabalhos economicamente valiosos, ou superinteligência, IA ainda mais inteligente do que os seres humanos podem compreender.
ATUALIZE: Venha discutir os últimos avanços e pesquisas de LLM no VB Transform nos dias 24 e 25 de junho em San Francisco — ingressos limitados disponíveis. REGISTRE-SE AGORA
Não é surpreendente que o artigo tenha circulado amplamente entre a comunidade de aprendizado de máquina na X e a reação inicial de muitos leitores foi declarar que a Apple efetivamente desmentiu grande parte da hype em torno desta classe de IA: “A Apple apenas provou que modelos de raciocínio como Claude, DeepSeek-R1 e o3-mini não raciocinam de fato”, declarou Ruben Hassid, criador do EasyGen, uma ferramenta de auto-escrita de postagens no LinkedIn movida por LLM. “Eles apenas memorizam padrões muito bem.”
Mas agora, um novo artigo surgiu, intitulado de maneira irônica “A Ilusão da Ilusão do Pensar” — co-autoria de um LLM de raciocínio, Claude Opus 4, e Alex Lawsen, um pesquisador e escritor técnico humano independente — que inclui muitas críticas da comunidade ML em relação ao artigo e argumenta efetivamente que as metodologias e os designs experimentais usados pela equipe de pesquisa da Apple em seu trabalho inicial são fundamentalmente falhos.
Embora nós, da VentureBeat, não sejamos pesquisadores de ML e não estejamos preparados para afirmar que os pesquisadores da Apple estão errados, o debate tem sido, sem dúvida, animado e a questão sobre as capacidades de LRMs ou LLMs de raciocínio em comparação com o pensamento humano parece longe de ser resolvida.
Como foi projetado o estudo de pesquisa da Apple — e o que ele encontrou
Usando quatro problemas de planejamento clássicos — Torre de Hanói, Mundo de Blocos, Cruzamento de Rio e Saltos de Damas — os pesquisadores da Apple projetaram uma série de tarefas que forçaram os modelos de raciocínio a planejar múltiplos movimentos à frente e gerar soluções completas.
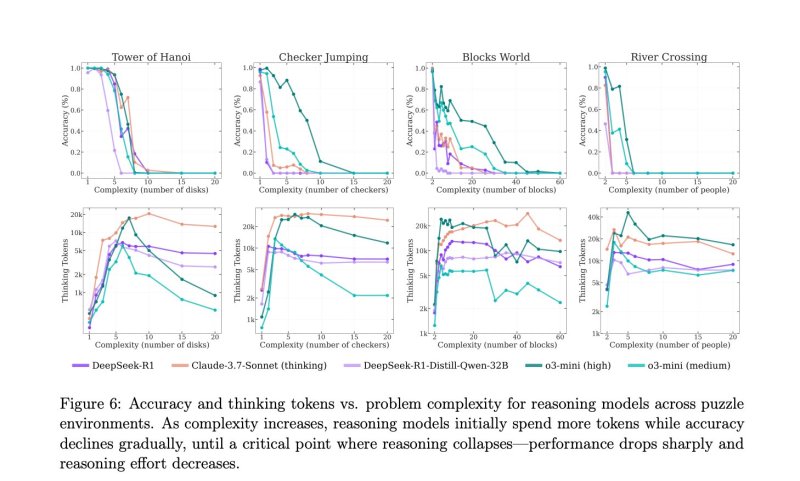
Esses jogos foram escolhidos por sua longa história na ciência cognitiva e pesquisa em IA, além de sua capacidade de escalar em complexidade à medida que mais etapas ou restrições são adicionadas. Cada quebra-cabeça exigiu que os modelos não apenas produzissem uma resposta final correta, mas também explicassem seu raciocínio ao longo do caminho, usando o prompting em cadeia de pensamento.
À medida que os quebra-cabeças aumentavam em dificuldade, os pesquisadores observaram uma queda consistente na precisão entre vários modelos de raciocínio líderes. Nas tarefas mais complexas, o desempenho caiu a zero. Notavelmente, o comprimento das trilhas de raciocínio internas dos modelos — medido pelo número de tokens gastos pensando sobre o problema — também começou a encolher. Os pesquisadores da Apple interpretaram isso como um sinal de que os modelos estavam abandonando a solução do problema completamente uma vez que as tarefas se tornavam muito difíceis, essencialmente “desistindo”.
O lançamento do artigo, logo antes da Conferência Anual de Desenvolvedores da Apple (WWDC), aumentou o impacto. Ele rapidamente se tornou viral na X, onde muitos interpretaram as descobertas como uma admissão de alto nível de que os LLMs de geração atual ainda são motores de autocompletar glorificados, e não pensadores de propósito geral. Essa moldura, embora controversa, impulsionou muito da discussão inicial e do debate que se seguiu.
Críticos atacam na X
Entre os críticos mais vocais do artigo da Apple estava o pesquisador de ML e usuário da X @scaling01 (também conhecido como “Lisan al Gaib”), que postou várias threads dissecando a metodologia.
Em um post amplamente compartilhado, Lisan argumentou que a equipe da Apple confundiu falhas de orçamento de tokens com falhas de raciocínio, observando que “todos os modelos terão 0 de precisão com mais de 13 discos simplesmente porque não conseguem produzir esse volume!”
Para quebra-cabeças como a Torre de Hanói, ele enfatizou que o tamanho da saída cresce exponencialmente, enquanto as janelas de contexto do LLM permanecem fixas, escrevendo “só porque Tower of Hanoi exige exponencialmente mais passos do que os outros, que exigem apenas mais passos quadráticos ou lineares, não significa que Tower of Hanoi seja mais difícil” e demonstrou de forma convincente que modelos como Claude 3 Sonnet e DeepSeek-R1 frequentemente produziam estratégias algoritmicamente corretas em texto simples ou código — mas ainda eram marcados como errados.
Outro post destacou que até mesmo dividir a tarefa em passos menores e decompostos piorava o desempenho do modelo — não porque os modelos falharam em entender, mas porque não tinham memória dos movimentos e estratégias anteriores.
“O LLM precisa da história e de uma grande estratégia”, escreveu, sugerindo que o verdadeiro problema era o tamanho da janela de contexto em vez do raciocínio.
Eu levantei outra questão importante eu mesmo na X: A Apple nunca avaliou o desempenho do modelo em comparação com o desempenho humano nas mesmas tarefas. “Estou perdendo algo, ou vocês não compararam os LRMs com o desempenho humano nas mesmas tarefas?? Se não, como sabem que essa mesma queda de desempenho não acontece com pessoas também?” Perguntei diretamente aos pesquisadores em uma thread marcando os autores do artigo. Eu também enviei um e-mail a eles sobre isso e muitas outras perguntas, mas ainda não obtive resposta.
Outros ecoaram esse sentimento, observando que solucionadores humanos também falham em quebra-cabeças longos e multietapas de lógica, especialmente sem ferramentas de caneta e papel ou auxiliares de memória. Sem essa base, a afirmação da Apple de um “colapso de raciocínio” fundamental parece infundada.
Vários pesquisadores também questionaram a moldura binária do título e tese do artigo — traçando uma linha dura entre “combinação de padrões” e “raciocínio.”
Alexander Doria, também conhecido como Pierre-Carl Langlais, um treinador de LLM na startup francesa de IA energeticamente eficiente Pleias, disse que a moldura perde a nuance, argumentando que os modelos podem estar aprendendo heurísticas parciais em vez de apenas combinar padrões.
Ethan Mollick, o professor focado em IA na Wharton School da Universidade da Pensilvânia, chamou a ideia de que os LLMs estão “barrando um muro” prematura, comparando-a a alegações semelhantes sobre “colapso de modelo” que não se concretizaram.
Enquanto isso, críticos como @arithmoquine foram mais cínicos, sugerindo que a Apple — atrás da curva em relação a LLMs se comparada a rivais como OpenAI e Google — poderia estar tentando diminuir expectativas, elaborando pesquisas sobre “como tudo é falso e não importa de qualquer forma”, apontando para a reputação da Apple com produtos de IA mal desenvolvidos como a Siri.
Em resumo, enquanto o estudo da Apple desencadeou uma conversa significativa sobre rigor de avaliação, também expôs uma profunda divisão sobre quanto confiar em métricas quando o teste em si pode ser falho.
Um artefato de medição ou um teto?
Em outras palavras, os modelos podem ter entendido os quebra-cabeças, mas esgotaram o “papel” para escrever a solução completa.
“Limites de tokens, não lógica, congelaram os modelos”, escreveu o pesquisador Rohan Paul, da Carnegie Mellon, em uma thread amplamente compartilhada resumindo os testes de acompanhamento.
No entanto, nem todos estão prontos para isentar os LRMs da acusação. Alguns observadores apontam que o estudo da Apple ainda revelou três regimes de desempenho — tarefas simples onde o raciocínio adicional prejudica o desempenho, quebra-cabeças de média complexidade onde ajuda, e casos de alta complexidade onde tanto modelos padrão quanto “pensantes” colapsam.
Outros veem o debate como uma posição corporativa, observando que os próprios modelos “Apple Intelligence” da Apple ficam aquém dos rivais em muitos rankings públicos.
A resposta: “A Ilusão da Ilusão do Pensar”
Em resposta às alegações da Apple, um novo artigo intitulado “A Ilusão da Ilusão do Pensar” foi lançado no arXiv pelo pesquisador independente e escritor técnico Alex Lawsen da Open Philanthropy, em colaboração com o Claude Opus 4 da Anthropic.
O artigo desafia diretamente a conclusão do estudo original de que os LLMs falham devido a uma incapacidade inerente de raciocinar em grande escala. Em vez disso, a refutação apresenta evidências de que o colapso de desempenho observado foi, em grande parte, um subproduto da configuração do teste — não um verdadeiro limite da capacidade de raciocínio.
Lawsen e Claude demonstram que muitas das falhas no estudo da Apple decorrem das limitações de tokens. Por exemplo, em tarefas como a Torre de Hanói, os modelos precisam imprimir uma quantidade exponencial de passos — mais de 32.000 movimentos para apenas 15 discos — levando-os a atingir tetos de saída.
A refutação aponta que o script de avaliação da Apple penalizou essas saídas por transbordo de tokens como incorretas, mesmo quando os modelos seguiram uma estratégia de solução correta internamente.
Os autores também destacam várias construções de tarefa questionáveis nas referências de benchmark da Apple. Alguns dos quebra-cabeças de Cruzamento de Rio, observam, são matematicamente insolúveis como formulados, e ainda assim as saídas dos modelos para esses casos foram pontuadas. Isso levanta ainda mais questões sobre a conclusão de que falhas de precisão representam limites cognitivos em vez de falhas estruturais nos experimentos.
Para testar a teoria, Lawsen e Claude realizaram novos experimentos permitindo que os modelos fornecessem respostas comprimidas e programáticas. Quando solicitados a gerar uma função Lua que pudesse criar a solução da Torre de Hanói — em vez de escrever cada passo linha a linha — os modelos de repente tiveram sucesso em problemas muito mais complexos. Essa mudança de formato eliminou o colapso completamente, sugerindo que os modelos não falharam em raciocinar. Eles simplesmente falharam em se conformar a um rubrica artificial e excessivamente rígida.
Por que isso importa para tomadores de decisão empresariais
A troca de argumentos destaca um consenso crescente: o design de avaliação agora é tão importante quanto o design de modelo.
Exigir que os LRMs enumere cada passo pode testar mais suas impressoras do que seus planejadores, enquanto formatos comprimidos, respostas programáticas ou blocos de anotações externos oferecem uma leitura mais limpa da verdadeira capacidade de raciocínio.
O episódio também destaca os limites práticos que os desenvolvedores enfrentam ao enviar sistemas agentes — janelas de contexto, orçamentos de saída e formulação de tarefas podem fazer ou quebrar o desempenho visível ao usuário.
Para tomadores de decisão técnicos empresariais que constroem aplicações baseadas em LLMs de raciocínio, esse debate é mais do que uma questão acadêmica. Ele levanta questões críticas sobre onde, quando e como confiar nesses modelos em fluxos de trabalho de produção — especialmente quando as tarefas envolvem cadeias de planejamento longas ou requerem saídas passo a passo precisas.
Se um modelo parece “falhar” em um prompt complexo, o problema pode não estar em sua capacidade de raciocínio, mas na forma como a tarefa é enquadrada, quanto output é exigido, ou quanto memória o modelo tem acesso. Isso é particularmente relevante para indústrias que estão construindo ferramentas como copilotos, agentes autônomos ou sistemas de apoio à decisão, onde tanto a interpretabilidade quanto a complexidade da tarefa podem ser altas.
Compreender as restrições das janelas de contexto, orçamentos de tokens e os rubricas usadas na avaliação é essencial para um design de sistema confiável. Os desenvolvedores podem precisar considerar soluções híbridas que externalizam a memória, dividem passos de raciocínio ou usam saídas comprimidas como funções ou código em vez de explicações verbais completas.
Mais importante ainda, a controvérsia do artigo é um lembrete de que benchmarking e aplicação do mundo real não são a mesma coisa. As equipes empresariais devem ser cautelosas para não depender excessivamente de benchmarks sintéticos que não refletem casos de uso práticos — ou que inadvertidamente restringem a capacidade do modelo de demonstrar o que sabe.
Por fim, a grande lição para pesquisadores de ML é que, antes de proclamar um marco de IA — ou um obituário — é necessário garantir que o teste em si não esteja colocando o sistema em uma caixa pequena demais para pensar dentro dela.


Conteúdo relacionado

Além da arquitetura GPT: Por que a abordagem de Difusão do Google pode redefinir a implementação de LLMs
[the_ad id="145565"] Participe do evento confiável por líderes empresariais há quase duas décadas. O VB Transform reúne pessoas que estão construindo uma verdadeira estratégia…

O Ato RISE do Senador exigiria que desenvolvedores de IA listassem dados de treinamento e métodos de avaliação em troca de ‘porto seguro’ contra processos judiciais.
[the_ad id="145565"] Participe do evento confiável por líderes empresariais há quase duas décadas. O VB Transform reúne as pessoas que estão construindo uma verdadeira…

O argumento a favor da incorporação de trilhas de auditoria em sistemas de IA antes da escalabilidade
[the_ad id="145565"] Participe do evento que é confiável por líderes empresariais há quase duas décadas. O VB Transform reúne as pessoas que estão construindo estratégias…